目录
🤔
Toss a Fault to Your Witcher: Applying Grey-box Coverage-Guided Mutational Fuzzing to Detect SQL and Command Injection Vulnerabilities
Abstract
黑盒网络应用程序漏洞扫描器试图在没有访问源代码的情况下自动识别Web应用程序中的漏洞。然而,它们通过使用手动策划的漏洞诱发输入列表来实现,这显著降低了黑盒扫描器探索Web应用程序输入空间的能力,并可能导致误报。此外,黑盒扫描器必须尝试推断是否触发了漏洞,这会导致误报。
为了克服这些限制,我们提出了一种新颖的Web漏洞发现框架,称为Witcher,受到灰盒覆盖引导模糊测试的启发。Witcher实现了故障升级的概念,以检测SQL和命令注入漏洞。此外,Witcher捕获覆盖信息并创建基于输出的输入指导,以便集中输入生成,从而增加Web应用程序的状态空间探索。在一个包含18个使用PHP、Python、Node.js、Java、Ruby和C编写的Web应用程序的数据集上,其中有13个已知漏洞,Witcher能够找到36个已知漏洞中的23个(64%),并且还发现了67个以前未知的漏洞,其中有4个获得了CVE编号。在我们的实验中,Witcher在发现漏洞数量和Web应用程序覆盖范围方面均优于现有技术的扫描器。
1. Introduction
随着Web应用程序数量的不断增加和支持的框架不断多样化,Web应用程序漏洞并未显示出减少的迹象。这些Web漏洞,如SQL注入,可能对Web应用程序的开发人员、运行Web应用程序的公司以及访问并在网站应用程序上存储数据的最终用户造成灾难性影响。
由于Web应用程序的数量和多样性,创建自动发现Web漏洞的技术至关重要。之前的研究提出了不同的爬行和检测技术,其中使用了以下方法之一:白盒[1],[2],[3],[4],黑盒[5],[6],[7],[8]和灰盒[9],[10]。然而,这些方法在适用于Web应用程序语言、漏洞类型或应用程序输入方面存在局限性。
白盒静态分析工具[1],[2],[3],[4]依赖于分析Web应用程序的源代码,但源代码并不总是可用。此外,白盒工具通常对特定语言的语义建模,这使得它们具有特定于语言的特点,因此将这些工具应用于新的语言或框架需要投入大量的努力。
黑盒网络应用程序漏洞扫描器[5],[6],[7],[8]无需源代码,可以分析任何Web应用程序,而不考虑Web应用程序的编程语言。这些工具会生成合法的Web应用程序输入来探索应用程序,然后尝试通过发送设计用于触发漏洞的输入到Web应用程序来推断漏洞的存在。然而,导致漏洞的输入受到显著限制,因为它们来自基于漏洞类型的专家启发式规则的手动策划的字符串或模板[11]。因此,黑盒扫描器将会错过由预先配置的字符串和模板之外的输入触发的漏洞。实质上,使用固定的漏洞诱发输入显著降低了黑盒扫描器探索Web应用程序输入空间的能力,从而引入了误报。
更糟糕的是,黑盒扫描器只能根据Web应用程序的输出推断漏洞。这样的推断可能会出现错误。例如,考虑一个返回HTTP 500状态代码(表示内部服务器错误)的Web应用程序。现有的黑盒扫描器如Burp [5]使用此错误代码来判断他们的漏洞诱发输入是否成功触发了漏洞。在寻找SQL注入漏洞的黑盒扫描器的情况下,HTTP 500错误可能表明输入导致了SQL错误。然而,这种错误可能是由其他无关问题引起的,比如实现错误而不是安全漏洞。因此,从外部推断漏洞会引入误报。
最近的一些研究引入了灰盒模糊测试工具的概念,用于自动测试Web应用程序[9],[10]。这些工具使用覆盖率信息来指导输入的生成。这些工具取得了一些成功,但这些方法只针对单一语言,无法检测SQL或命令注入漏洞,并且是闭源的[9],而且相对较慢[10]。
在本文中,我们提出了一种名为Witcher的新型Web漏洞发现框架,受到灰盒覆盖引导模糊测试的启发。我们的思想是通过使用执行覆盖率信息来高效地引导随机输入的生成,从而探索Web应用程序的输入空间(而不仅仅依赖于硬编码的启发式规则)。
将灰盒覆盖引导模糊测试应用于Web漏洞面临着许多挑战。从高层次上看,Web模糊测试面临的挑战是因为目标测试中包含感兴趣的漏洞的执行对象,即Web应用程序代码,并不是整个执行对象,而是一个小的子组件。在对二进制文件进行模糊测试时,整个二进制文件既是执行对象又是目标测试对象(即安全分析人员正在分析二进制文件中是否存在漏洞)。然而,在模糊测试Web应用程序时,执行对象包含三个组件:解析HTTP请求的Web服务器;使用来自Web服务器的输入生成响应的Web应用程序运行环境;以及数据存储和本地执行器,Web应用程序的逻辑使用它来完成请求。对于大多数Web应用程序,Web应用程序运行环境分解为两个子组件:Web应用程序代码和代码的执行环境(例如解释器或虚拟环境)。Web应用程序代码是Web应用程序运行环境的子组件,是包含Web应用程序逻辑和漏洞的目标测试对象。多组件的特性以及其他非目标组件会引发多个挑战,阻碍了将灰盒覆盖引导模糊测试应用于发现Web漏洞。
Detecting the input that triggers a web application vulnerability 检测输入是否会触发漏洞需要一个工具来推断系统是否处于一个易受攻击的程序状态。在检测内存损坏漏洞时,传统的二进制模糊测试使用分段错误作为指示,表明发送到二进制文件的输入将系统转换为易受攻击的程序状态。当前的黑盒扫描器方法使用启发式方法来推断给定的输入是否会触发易受攻击的程序状态。因此,一个关键的挑战是创建一种方法,可以识别将输入导入Web应用程序时是否会使其进入易受攻击的程序状态。
Generating feasible inputs for end-to-end execution 由于执行对象由Web服务器和Web应用程序代码组成,成功的输入必须满足两个组件(即对于Web服务器而言,它是一个有效的HTTP请求,同时还必须包含Web应用程序逻辑所需的输入参数)。尽管从理论上讲,随机输入生成方案最终将产生可行的输入,但设计一种能够为目标Web应用程序生成在语法和语义上都有效的输入的方法至关重要,从而有效地进行模糊测试。
Collecting effective web application coverage 灰盒覆盖引导模糊测试用于二进制应用程序的一个优势在于,模糊器只会保留对应用程序的新代码进行随机生成的输入,并且收集这种覆盖率信息是现代模糊测试的关键部分[12],[13]。一种可能的收集Web应用程序覆盖率的方法是在Web应用程序中插入仪表代码。然而,这种方法通常不适用于所有Web应用程序,不具备可扩展性,并且需要源代码,而源代码并不总是可用的。为了解决Web应用程序覆盖率统计的问题,需要一种可扩展且与Web应用程序无关的方法。
Mutating inputs effectively 与二进制模糊测试类似,灰盒覆盖引导模糊测试器的变异策略对于有效地模糊Web应用程序也是重要的。然而,目前对于Web应用程序的变异策略研究较少。因此,我们需要创建能够生成高质量新输入并增加模糊测试效果的变异策略。
Witcher的设计目标是解决前述的四个挑战。它不需要各个Web应用程序的源代码,并且我们展示只需对语言解释器进行1-5行的更改即可实现有效的代码覆盖。然后,这种更改可以用于运行在该解释器上的任何Web应用程序。为了演示我们的方法,我们为使用PHP、Python、Node.js、Java、Ruby和C编写的Web应用程序实现了Witcher的支持。对于这些语言中的每一种,Witcher都能够检测出SQL注入和命令注入漏洞。
为了展示Witcher相对于当前最先进技术的优势,我们进行了多方面的评估。我们比较了Witcher的不同配置,启用和禁用不同功能以展示这些功能的效果。我们在13个已知漏洞的Web应用程序和5个没有已知漏洞的现代Web应用程序上评估了Witcher。总体而言,Witcher总共发现了90个漏洞,其中有67个以前未知。然后,我们将Witcher的代码覆盖率和漏洞发现与商业的黑盒Web漏洞扫描器Burp [5]进行了比较,在九个PHP Web应用程序上进行了比较。最后,我们将Witcher的代码覆盖率与最近发布的黑盒漏洞扫描器Black Widow [14]和灰盒扫描器WebFuzz [10]进行了比较。总之,我们做出了以下贡献:
- 我们创造了一项新技术,解决了将灰盒覆盖引导模糊测试应用于Web应用程序时所面临的挑战,并提出了一个新的框架,使覆盖引导模糊测试适用于Web应用程序
- 我们开发了Witcher,一个灰盒Web应用程序漏洞模糊测试工具,可以从不同的Web应用程序中发现多种类型的漏洞。Witcher可以自动分析使用PHP、JavaScript、Python、Java、Ruby和C编写的服务器端二进制和解释型Web应用程序,并检测SQL注入、命令注入和内存损坏漏洞(仅适用于基于C的CGI二进制文件)。
- 我们进行了Witcher的评估,以了解各种技术所取得的具体影响,方法在现实世界的Web应用程序上的有效性,以及其在分析非传统目标(如物联网设备)方面的适用性。在我们的评估中,Witcher成功识别出36个已知漏洞中的23个,这超过了现有的Web漏洞发现工具。此外,在除一个Web应用程序外,Witcher的代码覆盖范围都超过了现有技术的扫描工具Black Widow和WebFuzz。Witcher还识别出了67个以前未知的漏洞,我们正在与相关方披露这些漏洞。
为了支持开放科学和未来领域内的研究人员,我们将在发表本论文后开源我们的Witcher原型、Web应用程序数据集以及实验结果。
2. Background
在我们讨论Witcher的细节之前,我们首先介绍Web应用程序和注入漏洞,然后提供自动应用程序测试和覆盖引导模糊测试的高级概述。
2.1. Web Applications and Vulnerabilities
通常,Web应用程序在Web服务器上运行,并通过网络与其客户端进行交互。客户端通过向Web服务器发送HTTP请求来访问Web应用程序,Web服务器解析并将请求路由到Web应用程序。Web应用程序接受输入,执行适当的操作,并对请求做出响应。在这种架构中,Web服务器充当Web应用程序的网关,而Web应用程序可以用任何编程语言编写。Witcher使用HTTP请求或直接的Custom Gateway Interface(CGI)请求来访问Web应用程序资源。
HTTP Requests HTTP是一种无状态的客户端-服务器协议,被Web服务器使用[15]。一个HTTP请求由一个请求行、零个或多个头字段以及一个可选的消息主体组成。尽管Web应用程序不仅限于此,但通常会通过Cookie头(用于建立有状态请求)、URL查询参数(用&分隔的name=value键值对列表)和HTTP主体(用&分隔的name=value键值对列表)来接受用户输入。为了简化起见,我们将所有用于传输用户输入的方法(头部、URL查询字符串和HTTP主体)统称为HTTP参数或简称为参数。
CGI Requests 自定义网关接口(CGI)使Web服务器能够通过将HTTP请求转换为CGI请求(其中HTTP请求的各个方面可以通过环境变量和标准输入访问)来直接调用可执行程序[16]。尽管许多Web应用程序已将CGI替换为FastCGI、Apache模块和NSAPI插件[17],但CGI应用程序仍广泛用于嵌入式设备,例如路由器和网络摄像头[18]。
Injection Vulnerabilities 注入漏洞是代码和数据混合的一种情况[19],当Web应用程序将未经过过滤的用户数据发送到外部解析器时,比如将数据发送到Shell来执行命令或发送到数据库来执行SQL查询时,就会出现这种漏洞。恶意的攻击者可以通过提供用户输入来利用这种漏洞,以欺骗外部解析器,将用户提供的数据误解为代码,从而改变解析的语义。
在SQL注入漏洞中,攻击者发送一个格式正确的有效载荷,其中包含了SQL代码作为他们的输入,这个输入会作为SQL查询发送到数据库。当数据库执行查询时,也会执行攻击者注入的SQL代码。同样,在命令注入漏洞中,攻击者创建的有效载荷会导致额外的Shell命令被执行。
2.2. Motivating Example
请考虑附录中的清单1中的PHP Web应用程序,我们根据现实世界的Web应用程序和CVE(在§ 5.2中描述)中存在的模式创建了这个应用程序。根据页面的目的,它为用户提供不同的表单字段。对于对数据库的添加,它包括pname和ptype。对于对数据库的更新,它包括pid和ptype。然而,在这个例子中,更新功能从Web应用程序前端被移除,但保留在服务器端的PHP中。因此,客户端界面不提供任何有关更新功能的提示,这使得黑盒漏洞扫描器很难触发潜在的PHP更新代码。
清单1中的代码包含三个SQL注入漏洞,商业的黑盒漏洞扫描器Burp无法检测出来。第一个漏洞存在于添加功能中。成功的攻击需要在ptype字段的前半部分发生变化,该字段在SQL语句中被使用但未经过过滤处理。第二个漏洞出现在潜在的PHP更新代码中。为了利用这个漏洞,攻击者必须发现更新操作,并使用ptype字段的color部分来利用漏洞。最后一个漏洞需要使用添加和更新功能,因为更新代码要求数据库中必须存在pid,但对pid的格式没有施加任何限制。因此,攻击者将有效载荷插入数据库中的pid字段,然后触发更新来利用第三个漏洞。

黑盒漏洞扫描器很可能无法发现这三个漏洞。它不太可能发现第一个漏洞,因为要到达该漏洞,ptype变量必须包含一个下划线,在扫描器预定义的负载列表中不存在下划线。此外,黑盒扫描器很难发现其他漏洞,因为客户端界面不包括触发更新所需的值。
尽管如此,Witcher自动地找到了这三个漏洞。Witcher通过变异有效输入来找到第一个漏洞,使其包含下划线和会导致产生格式错误SQL语句的值。在解析格式错误的SQL时,Witcher会检测到该漏洞。Witcher找到其他两个漏洞是因为在模糊测试过程中,它会将act的值变异为'u',并将输入标记为感兴趣,因为act=u导致了以前未见过的程序状态。然后,Witcher会专注于感兴趣的输入,这将使Witcher通过添加格式错误的ptype触发第二个漏洞,并通过使用以'a'操作存储到pid列中的格式错误的pid值触发第三个漏洞。尽管第三个漏洞需要应用程序进入特定的状态,但Witcher并不分析应用程序的状态;相反,Witcher触发该漏洞是因为数据库在请求之间保持了正确的状态。
2.3. Automated Application Testing
自动化应用程序测试分为三种不同的类别,这些类别取决于测试技术对应用程序的访问程度:黑盒、白盒和灰盒。在黑盒测试中,测试运行时没有访问目标应用程序的内部[13]。因此,黑盒测试仅关注应用程序的输入和输出[20]。例如,黑盒Web漏洞扫描器,如Burp或Skipfish,从Web应用程序的外部工作以发现新的输入[21]。
在另一极端,白盒工具通过分析应用程序的源代码来生成输入,目的是更好地理解应用程序的语义[13]。一些白盒分析的例子包括符号执行和污点跟踪[22],[23],[24]。白盒工具可以访问目标应用程序的源代码。因此,白盒工具可以推理应用程序的内部结构和操作,并且可以在不受限于执行期间可达到的路径的情况下评估操作;然而,它们专注于特定的编程语言,并且往往容易出现误报。
灰盒测试模糊了白盒和黑盒测试之间的界限,因为它在有限的应用程序访问权限下运行。测试应用程序使用较少强度的静态分析或动态分析形式。例如,覆盖引导的变异模糊测试使用静态或动态插桩来收集覆盖率信息,该信息用于识别在程序中执行新执行路径的输入(从而打破了纯黑盒方法)。
2.4. Coverage-Guided Fuzzing
模糊测试工具通过输入测试用例并导致目标应用程序进入不同的程序状态来自动测试应用程序。当模糊器启动时,它会接收一组输入种子,并将其放入测试用例队列中。然后,模糊器从队列中派生新的测试用例。
要从队列中的测试用例派生出一个新的测试用例,模糊器使用各种变异策略对测试用例进行变异。例如,American Fuzzy Lop (AFL) 使用确定性的变异策略,如位翻转、整数算术和字典插入[25]。此外,AFL还使用随机策略,如随机拼接和从用户提供的字典插入数据。在变异输入之后,模糊器将修改后的输入发送给目标应用程序。
在覆盖引导的模糊测试中,模糊器捕获近似于程序状态的覆盖率数据,以指导测试用例的选择。模糊器捕获的覆盖率数据近似于程序状态,但比执行轨迹要不完整得多。之所以近似于程序状态,是因为对于模糊器来说,捕获和分析每次执行的完整执行轨迹过于处理密集。模糊器通过静态或动态插装获取覆盖率数据。对于静态插装,分析人员使用修改过的编译器编译目标应用程序的源代码。对于动态插装,动态插装工具(如Pin)或修改过以提供覆盖率数据的模拟器(如QEMU-user)在执行过程中产生覆盖信息[26],[27]。
覆盖引导的模糊器会在认为测试用例有趣时保存该测试用例。当测试用例导致程序达到一个新的位置,或者导致应用程序发出致命信号(例如分段错误),模糊器会将测试用例标记为有趣。通常,这意味着应用程序进入了一个易受攻击的状态。
3. Challenges
创建灰盒覆盖引导的Web应用程序漏洞模糊器存在固有的挑战。我们将这些挑战分为两组,一组是关于实现自动化分析的,另一组是关于增强输入空间探索的。
3.1. Enabling Fuzzing of Web Applications
实现对Web应用程序的自动分析需要模糊器生成能够到达目标应用程序的输入,并检测漏洞的存在。
- **How to detect web injection vulnerabilities? ** 模糊器的目标是识别何时测试用例会导致程序进入易受攻击的程序状态。通常,由SQL和命令注入漏洞引起的故障不会导致模糊器能够检测到的错误信号,它们经常发生在一个单独的进程中(例如数据存储层)。因此,我们必须开发一种新的方法,使模糊器能够检测到SQL和命令注入漏洞。
- How does the system generate a test case that will exercise an end-to-end execution of the web application? Web应用程序要求测试用例与半结构化格式匹配,以通过Web服务器的语法检查和Web应用程序的语义。相比之下,变异模糊器生成高熵的随机数据,无法有效地探索应用程序的输入空间。如果不对测试用例强制施加一些结构,模糊器将无法探索Web应用程序的状态空间。首先,如果测试用例未能满足HTTP请求格式,那么测试用例将无法到达目标Web应用程序,因为Web服务器将拒绝它(参见 § 2.1)。其次,测试用例必须包含目标应用程序所期望的参数。如果没有参数变量名称,那么合理地探索目标的输入空间是不可能的,因为模糊器将生成数十亿个测试用例,仅仅是为了随机猜测只有几个字符的单个变量名称。
3.2. Augmenting Fuzzing for Web Injection Vulnerabilities
即使模糊器满足了上述挑战,以启动对Web应用程序的模糊测试,添加这些特性还不足以有效地探索目标的输入空间并发现漏洞。使用覆盖引导的变异模糊器对应用程序进行分析是一个计算密集型的任务,尽管有许多资源,但其使用往往只能探索部分输入空间。对于Web应用程序来说,这个问题甚至更加严重,因为模糊器不能从目标Web应用程序代码中获取执行轨迹信息,且模糊器不能有效地变异参数和值。
- How to effectively collect coverage of the web application? 覆盖率引导的模糊器需要对目标应用程序进行插桩以收集覆盖率信息。然而,在模糊解释性语言编写的应用程序的情况下,很少有工具可以进行目标Web应用程序的插桩。相反,模糊器会对解释器的运行时二进制代码进行插桩,而不是对目标Web应用程序代码进行插桩。因此,覆盖信息反映了解释器的代码,而不是目标Web应用程序,这使得模糊器集中于探索运行时解释器的代码,而不是Web应用程序的代码。尽管随着对Web应用程序执行的更改,解释器的覆盖范围会发生变化,但覆盖数据的很大部分是无关的噪声,会混淆目标Web应用程序的覆盖信息。因此,为了促进对Web应用程序的探索,插桩必须只报告目标Web应用程序的执行情况。
- How to effectively mutate test cases? 尽管对于生成二进制应用程序输入的测试用例而言,模糊器使用的变异策略专注于创建高熵的测试用例,这些测试用例不需要上下文。然而,这些高熵测试用例对于探索Web应用程序的输入状态空间效果较差。即使高熵测试用例是正确构造的HTTP请求,它们在测试Web应用程序时效果有限,因为它们未能充分利用客户端可用的上下文信息(例如在HTML表单字段中找到的变量名)。因此,有必要创建新的变异策略,以整合正确的格式,并利用Web应用程序客户端接口提供的上下文信息。
4. Witcher’s Design
Witcher是一个灰盒式Web漏洞扫描器,使用覆盖引导的变异模糊器来驱动对Web应用程序的自动化探索。Witcher被归类为灰盒模糊器,因为类似于传统的覆盖引导模糊,它依赖于覆盖数据来识别有趣的测试用例。除了为覆盖数据对解释器进行插装外,Witcher不对源代码执行任何分析;因此,Witcher可以在没有任何源代码访问权限的情况下运行,因为它可以运行Web应用程序的字节码版本。由于许多二进制模糊研究以AFL为起点,我们选择使用AFL作为基础来展示Witcher框架的效能。
Witcher通过五个附加组件解决了阻碍覆盖引导变异模糊使用的挑战(在第3部分中描述)。为了启用针对Web注入漏洞的模糊测试,Witcher实现了"Fault Escalator"、"HTTP Harness"和"Request Crawler"(图1中的蓝色组件)。为了增强针对Web注入漏洞的模糊测试,Witcher实现了"Coverage Accountant"和"HTTP Mutator"(图1中的绿色组件)。
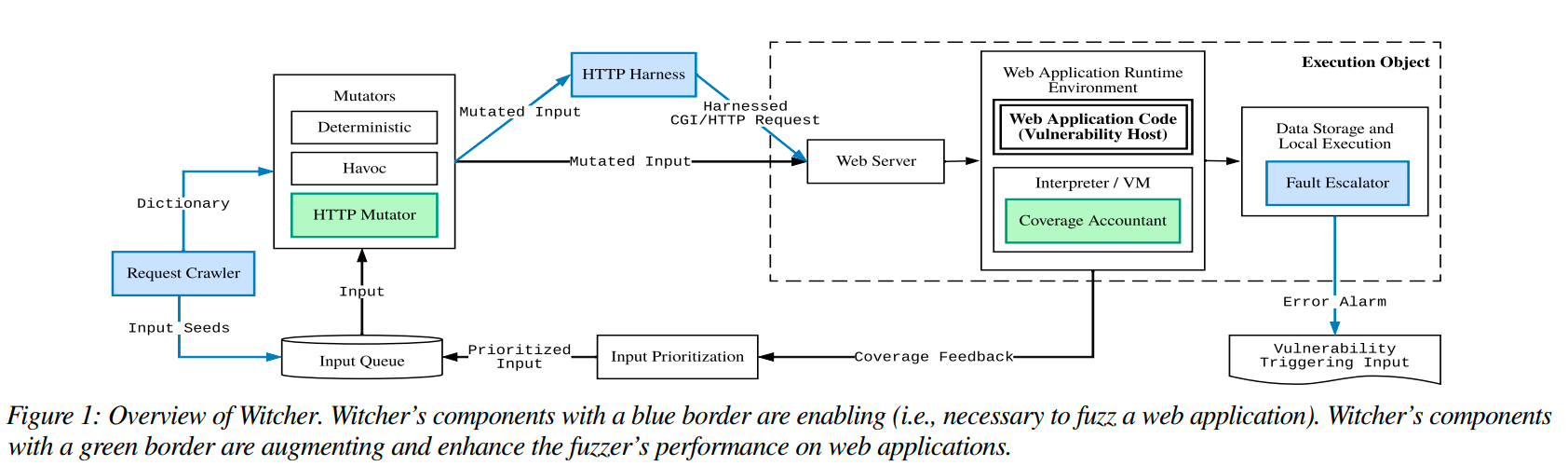
4.1. Enabling Fuzzing for SQL and Command Injection Vulnerabilities
4.1.1. Fault Escalator 为了使程序不受漏洞影响,用户提供的输入必须无法将程序转换为易受攻击的程序状态,因此通过识别易受攻击的程序状态的发生,扫描器可以检测目标应用程序中的漏洞。在传统的二进制模糊测试中,易受攻击状态是由内存损坏漏洞引起的,而二进制模糊器通过检测分段错误信号来检测是否发生了向易受攻击状态的过渡[13]。
我们利用这一见解并将概念扩展,以使模糊器能够检测程序是否转换为由SQL或命令注入漏洞引起的易受攻击的程序状态。SQL和命令注入漏洞发生在用户输入导致外部解析器(命令注入的情况下为shell命令解析,SQL注入的情况下为SQL解析)将用户输入数据解释为代码。例如,当攻击者控制的输入改变SQL查询的语法时,就会发生SQL注入漏洞。在格式良好的SQL查询中,用户控制的输入不能改变SQL查询的语法。因此,我们可以将外部解析器引发的语法错误视为内存损坏漏洞引发的分段错误信号的类比。这种关联形成了"Fault Escalator"的基础:如果攻击者控制的输入在外部解析器中引发语法错误,那么攻击者可以更改命令,并且很有可能存在可利用的漏洞。因此,当发生解析错误时,"Fault Escalator"将错误升级为分段错误,通知模糊器当前的测试用例导致了易受攻击的程序状态。例如,想象一个执行mysqli_query(\$con,"SELECT ID from tbl where ID=". \$_GET['id'])的PHP应用程序,而模糊器将id=1'设置为一个输入,由于单引号导致了一个格式不正确的SQL语句。当页面执行SQL语句时,SQL解析器会返回一个解析错误,该错误被"Fault Escalator"拦截并升级为模糊器检测到的分段错误。
如果一个应用程序使用未经过滤的输入创建SQL语句或shell命令,那么模糊器生成的随机输入很可能会导致解析错误。尽管并非模糊器生成的每个输入都会在易受攻击的查询中导致SQL语法错误,但考虑到模糊器的随机性质,在模糊测试会话期间,一个易受攻击的查询不太可能不会导致SQL解析错误。这也得到了我们的实验验证:Witcher未能发现的漏洞与"Fault Escalator"中的误报问题无关。
**Command Injection Escalation. **在命令注入方面,Witcher使用dash的命令解析器实现了故障升级。程序dash是Debian Almquist shell,旨在与POSIX兼容,并尽可能小。Dash在大多数Linux系统上替代了/bin/sh [28]。当应用程序执行shell命令时,Linux使用/bin/sh以及其较小的替代品dash。例如,使用exec()、system()或passthru()的PHP脚本,或者使用exec()的Node.js脚本,将其命令发送到/bin/sh,这意味着dash会解析并运行该命令。Witcher版本的dash(与原始版本相比仅有3行代码差异)将解析错误升级为分段错误。因此,如果应用程序使用未经过滤的用户输入创建SQL或shell命令,那么模糊器输入的随机数据会导致解析错误并触发分段错误。
SQL Injection Escalation. SQL 注入方面,Witcher的Fault Escalator通过类似命令注入升级的技术,实现了针对MySQL和PostgreSQL的SQL注入升级。为了捕获语法错误,Witcher使用LD_PRELOAD来挂钩libc库中的recv()函数,该函数用于与数据库通信。每当来自数据库的任何响应包含SQL语法错误消息时,Witcher会触发分段错误。
Fault Escalation is not Limited to Syntax Errors. 虽然SQL和命令注入检测的故障升级技术依赖于语法错误的存在,但错误升级的概念适用于任何类型的警告、错误或模式。例如,Witcher可能通过覆盖libc的open函数并在文件名参数包含非ASCII值时升级错误来处理文件包含。
Memory Corruption Vulnerabilities. Witcher在不使用错误升级的情况下,检测CGI二进制应用程序中的内存损坏漏洞。这是因为由于输入触发的分段错误,fuzzer在执行二进制应用程序时本质上会检测到内存损坏漏洞。
Bugs and Vulnerabilities. 与分段错误类似,由于用户输入而导致SQL语句或shell命令中的语法错误的发生表示应该修复的错误,并且高度可能是易受攻击的。在我们的评估中,语法错误的发生表明了用户输入的验证或净化存在问题,这通常意味着存在SQL注入或命令注入漏洞。 然而,由于用户输入的限制,攻击者可能无法利用语法错误来利用SQL注入或命令注入。例如,将未经净化的参数限制为仅能为一个字符的Web应用程序可能不代表一个可利用的漏洞,而只是一个错误。因此,在本文中,我们将任何升级的错误标记为漏洞或错误,具体取决于我们是否确认了漏洞是否可利用。
Cross-site Scripting Vulnerabilities. 故障升级技术利用模糊测试器生成的随机性来识别服务器环境中的关键性漏洞。不幸的是,跨站脚本漏洞并不容易归入这一类别(浏览器在解析HTML时非常宽容,因此要在HTML中可靠且快速地检测跨站脚本漏洞可能是困难的)。因此,我们选择关注命令注入和SQL注入。此外,SQL和命令注入漏洞代表了一类在我们之前的工作中基于变异的模糊测试器很难检测到的漏洞。
4.1.2. Request Crawler
Reqr(Request Crawler)是一个黑盒爬虫,旨在自主识别HTTP请求及其关联的参数。Reqr能够从各种类型的Web应用中提取HTTP请求,包括那些广泛使用客户端JavaScript构建用户界面的应用。它能够识别Web应用中的链接、表单、提交以及请求等各种组件(例如在第5节中讨论的Rconfig、Juice Shop和WebGoat等)。
Reqr的运作方式类似于黑盒漏洞扫描工具:它接收一个入口URL,可选地提供有效的登录凭证和登录URL。Reqr使用Node.js库Puppeteer(用于控制Chromium的API)来模拟用户操作并捕获请求 [29]。Reqr启动后,如果需要,它会登录到Web应用并加载入口页面。一旦页面加载完成,Reqr会对呈现的HTML进行静态分析,以识别创建HTTP请求或HTTP参数的HTML元素,如a、form、input、select和textarea。接下来,Reqr在模拟用户事件(例如鼠标点击、填写表单字段和滚动页面)的同时监听HTTP请求,无论是系统性地还是随机地。Reqr通过针对每个接受用户事件的HTML元素有系统地触发这些事件。此外,Reqr还使用Gremlins测试工具[30]随机触发用户输入事件(例如点击、表单填写、滚动和输入)。
当Reqr完成时,它会创建一个包含所有请求信息的文件。Witcher使用这些请求信息来创建模糊测试器的种子(初始测试用例)并构建模糊测试器的字典。
4.1.3. Request Harnesses
Witcher的HTTP harness将模糊测试器生成的输入转换为有效的请求。由于不同的执行模型,Witcher在处理PHP和CGI二进制文件方面与处理Python、Node.js、Java和基于QEMU的二进制文件方面具有不同的harness设计。对于PHP和CGI的web应用程序,Witcher将模糊测试器输入的格式转换为CGI请求。对于Python、Node.js、Java和基于QEMU的二进制文件,Witcher将模糊测试器的输入转换为HTTP请求(参见第2.1节)。
CGI Harness. 对于PHP(通过php-cgi)和CGI二进制文件,使用相同的harness,因为两者都依赖于CGI请求,并且调用的终端在被调用后会一直运行到完成。对于PHP和CGI二进制文件,HTTP harness使用LD_PRELOAD创建一个fork服务器,在处理输入之前,它会在解释器或二进制文件中启动进程。这个harness会从模糊测试器接收每个新的输入,将输入转换为CGI请求,然后将请求传递到新fork的进程中。
HTTP Request Harness. Witcher通过使用关联的HTTP请求Harness来对其他解释型语言和基于QEMU的Web应用进行模糊测试,通过这种方式,Witcher可以从目标平台上解耦,使其能够对不支持的应用程序进行测试。例如,AFL不能对使用Express的Node.js Web应用进行模糊测试,因为该应用程序会无限期运行,等待新的请求,并且是多线程的。
HTTP Request Harness在AFL和Web服务器之间建立了一个桥梁,以利用Web服务器对Web应用程序的接口。HTTP Harness包括其自己的Fork-Server,从而增加了请求提交的吞吐量。该Harness接收来自模糊测试器的输入,将该输入转换为格式良好的HTTP请求,并将HTTP请求发送到Web服务器。最后,当Fault Escalator检测到导致语法错误的SQL语句或shell命令时,Fault Escalator会发送一个分段错误到HTTP Harness进程,这会被模糊测试器自动检测到。
Translating Fuzzing Input into a Request. CGI Harness和HTTP Request Harness都充当了模糊测试器和Web应用程序之间的翻译器。Witcher自动为模糊测试器创建了遵循以空终止符分隔的格式的种子。这些种子包括用于Cookies、查询参数、POST变量和其他头部值的字段。因此,模糊测试器基于这个格式创建了测试用例,然后Harness将其转换为适当的请求类型。
除了处理模糊测试器的输入外,Harness还为输出请求设置了一些其他参数。Harness使请求路径对于每个模糊测试器实例保持静态,这意味着Witcher一次只对一个URL进行模糊测试。此外,Harness添加了任何必要的会话Cookie、查询变量或POST变量,以确保Web应用程序能够正常运行。例如,OpenEMR Web应用程序中的大多数端点都需要有效的登录会话。因此,在调用模糊测试器之前,Witcher会输入有效的登录凭据以生成有效的会话Cookie,然后Harness在每个请求中包含该会话Cookie。
4.2. Augmenting Fuzzing for Web Injection Vulnerabilities
4.2.1. Coverage Accountant
Witcher的覆盖率统计器(在图1右侧的Interpreter块内)为解释性语言(如PHP、JavaScript、Python和Java)以及可以使用QEMU-user或QEMU-system执行的Web应用程序提供了字节码执行覆盖率信息。Witcher使用覆盖率统计器是因为尝试通过对解释器进行插桩来进行模糊测试Web应用程序会产生大量噪音。例如,当我们使用AFL的标准方法对一个具有六个唯一路径的简单网页进行解释器插桩时,模糊测试器报告找到了一千多个唯一路径。这种差异是因为通过对解释器进行插桩,模糊测试器会集中于改变解释器的执行路径的测试用例;然而,改变解释器的执行路径通常并不等同于目标Web应用程序。尽管模糊测试器识别出的许多路径并不会为Web应用程序代码提供额外的覆盖率,但模糊测试器会存储并尝试对每个测试用例进行变异,因为它们改变了解释器的执行。等价测试用例的数量增加阻碍了模糊测试器在探索目标Web应用程序时取得有意义的进展。因此,Witcher创建了覆盖率统计器以更准确地捕获Web应用程序的执行路径。
**Interpreter Instrumentation. ** 尽管不同的解释器架构有所不同,但字节码的插桩在它们之间是相似的。解释器会读取源文件并将代码转换为字节码指令。接下来,解释器执行这些指令。
在执行指令期间,增强的解释器会调用Witcher的代码覆盖率库函数。Witcher的库函数接收当前字节码指令的行号、操作码和参数。然后,Witcher使用当前和先前指令的行号和操作码来更新模糊器的覆盖率信息。 Witcher的解释器插桩针对的是Web应用程序。在附录中的代码示例1中,代码有六条可见的路径,还有一些潜在路径存在于函数$_GET()、mysqli_query()和uniqid()中。因此,通过Witcher的PHP插桩,模糊器将找到六条它认为是独特的路径。
CGI Binaries. 除了解释性语言之外,Witcher还支持对 CGI 二进制程序进行模糊测试。对于 CGI 二进制程序,当二进制程序的源代码可用时,Witcher使用 AFL 的插桩技术。当源代码不可用时,Witcher 的模糊器使用 QEMU 进行动态插桩 [31]。尽管 QEMU 用户空间版本的插桩修改已经包含在 AFL 中,Witcher 对 QEMU 用户空间版本进行了额外的修改,以支持故障升级。对于 QEMU 系统空间版本,Witcher 的修改针对用于存储 QEMU 中间语言的数据结构,这个中间语言的处理方式类似于解释性语言使用的字节码。
Beyond AFL. Witcher将AFL用作覆盖引导的变异模糊测试工具;然而,Witcher框架可以整合更先进的模糊测试工具。如果一个新的模糊测试工具使用了改进的插桩技术,比如 PTrix [32],或者变异技术,比如 Tfuzz [33] 或 AFL++ [34],那么Witcher可以整合这些模糊测试工具,同时利用Web抓取和故障升级来检测比这些工具单独更广泛的漏洞类型。
4.2.2. HTTP-specific Input Mutations
我们通过添加两个新的变异阶段来修改AFL,这些阶段专注于操作HTTP参数。这些变异的目的是比标准AFL更快地将参数注入到输入中,并在变量级别上共享/交换值,而不是将参数视为一系列无结构字节的序列。实际上,这些变异器以更符合Web应用程序语法和语义的方式降低和调节了AFL的熵。
HTTP Parameter Mutator. HTTP参数变异器通过在fuzzer队列中存储的有趣测试用例之间交叉传播唯一的参数名称和值。Witcher一次只模糊一个URL终端点;然而,不同测试用例的变量之间通常存在相互依赖关系。通过交叉传播参数,fuzzer提供了更有针对性的测试用例,这些测试用例比随机字节变异更有可能触发新的执行路径。例如,在列表1中,如果一个测试用例包含act=a,另一个包含ptype=dog_red,那么通过组合它们,fuzzer将达到易受攻击的代码。
HTTP Dictionary Mutator. HTTP字典变异器减少了将当前输入与字典中的变量配对所需的执行次数。许多终端点具有多个用途,因此,一个终端点可能有多个使用不同HTTP变量的请求。对于给定的终端点,Witcher将Reqr发现的所有HTTP变量放入模糊字典中。HTTP字典变异器利用上下文相似的变量,通过将它们与当前请求进行混合匹配来执行此操作。HTTP字典变异器通过从字典中随机选择一个到十个变量,并将它们添加到当前测试案例中来实现这一点。
5. Evaluation
在本节中,我们通过对Witcher的评估来回答以下研究问题:
RQ1. Witcher的增强技术对于探索Web应用程序并识别漏洞的效果如何?这两种增强技术是否都有助于模糊测试(第5.1节)?
RQ2. Witcher在识别Web应用程序中的漏洞方面效果如何(第5.2节)?
RQ3. Witcher的代码覆盖率和漏洞发现与商业黑盒漏洞扫描器以及前沿漏洞扫描器相比如何(第5.3节)?
5.1. Witcher Augmentation Techniques Evaluation
为了更好地了解Witcher的增强功能对Web应用程序模糊测试的影响,我们使用不同的配置对Witcher进行评估,并在两个数据样本上进行测试。第一个样本是使用10个自创建的PHP脚本进行的微测试,第二个样本是一个真实的Web应用程序OpenEMR。
回想一下,我们设计了两种模糊测试增强技术:覆盖率统计和HTTP变异器。在这个实验中,我们使用了四种不同的Witcher配置:
AFLR 没有覆盖率统计和HTTP变异器。这个配置旨在作为与带有模糊测试增强的Witcher进行比较的基准。
AFLHR 具有HTTP变异,但不具备覆盖率统计。
WiCR 具有覆盖率统计,但不具备HTTP变异。
WiCHR 具有覆盖率统计和HTTP变异。
5.1.1. Microtest Evaluations.
在微型测试评估中,我们对每个配置在一组设计用于测试Witcher能力的十个PHP脚本上运行。每个脚本都包含一个到达注入漏洞的单一路径。针对特定配置的脚本评估运行直到达到目标注入漏洞或经过四个小时,以先到者为准。
字典模拟了Reqr生成的输出,其中包括每个脚本使用的参数,另外还包括100个未关联的参数以模拟未使用的变量。每个脚本和配置都运行了五次以稳定结果。
每个微型测试都针对Witcher的组件功能或增加了额外的难度。第一组脚本(post-2,post-5,post-10,get-5和cookie-5)遵循相同的一般格式,测试Witcher输入正在测试的变量类型的能力。例如,post-2(附录中的清单2)在isset($ _POST ['nv1'])和isset($ _POST ['nv2'])都返回true时,执行直接连接由$ _GET ['vul']返回的值的SQL语句(即未经过消毒的值)。结果,要通过测试,模糊测试器必须提供post变量nv1和nv2以及URL参数vul,其中包含会触发SQL解析错误的值。

接下来的一组脚本测试Witcher的特定变量和值的提供能力。为了达到select-3中的易受攻击的SQL语句,变量和值被提供在字典中(就像它们是由爬虫收集的一样),因为它们是通过<select>标签在用户界面上提供的。在equals-1、equals-3和loop-10测试中,达到易受攻击的SQL所需的值没有在用户界面中提供;因此,模糊测试器必须发现这些值。equals-1(附录中的清单3)执行易受攻击的SQL语句,该语句在$_GET['nv1'] == "YYYY"时连接未经过滤的输入变量$_GET['vul'],所需的值YYYY没有在字典中提供。类似地,在equals-3中,模糊测试器必须发现三个未知值才能达到易受攻击的语句。loop-10(附录中的清单4)使用for循环评估输入,以逐字节比较代替使用==来比较整个字符串,这为模糊测试器提供了一些线索以发现未知值并达到易受攻击的语句。最后一个测试与equals-1类似,只是模糊测试器提供了必要的值但没有变量名。findvar-1(附录中的清单5)在isset($_POST['ao3'])时执行易受攻击的语句;然而,a03在种子或字典中没有提供。一些微型测试脚本的摘录可在附录中找到。表1显示了微型测试的总体结果。根据结果,我们看到AFLR未能发现任何漏洞。它的性能较差,因为将仪器放置在解释器中产生的额外噪声大大减少了通过所有输入的循环次数,从而限制了它探索的字典值数量。




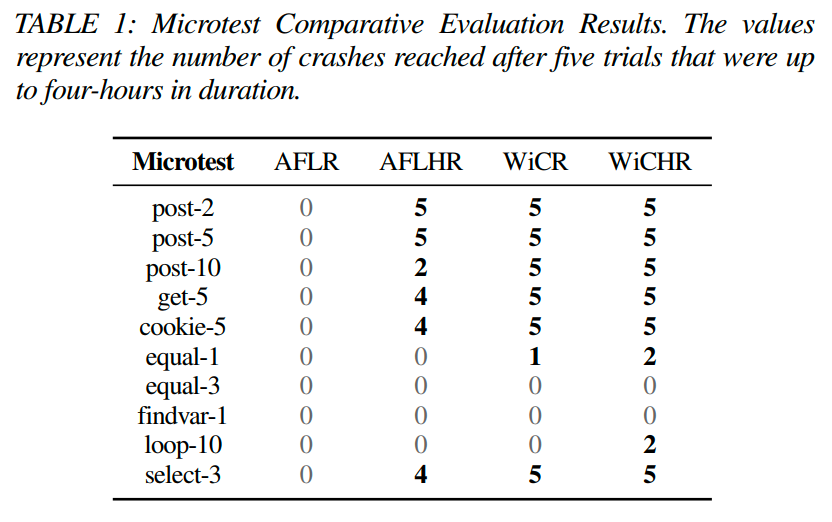
另一方面,WiCHR表现最佳。WiCHR共达到了34次漏洞。然而,在3个循环测试中,WiCHR无法找到漏洞,因为AFL不太关注包含重复指令的覆盖范围。因此,这两种增强技术有助于增加网络漏洞发现的效果,因此Witcher将在后续的评估中包括这两种技术。 我们使用Mann Whitney U-test 来验证不同配置之间的差异是否具有统计学意义[35]。由于我们选择运行直到第一个崩溃或超时,我们使用每次试验的累计经过时间来计算配置之间的差异。WiCHR配置在每次试验中所需的时间最少,并且相对于其他配置的改进在 Mann Whitney U-test 下具有统计学意义。
5.1.2. OpenEMR Evaluations
为了评估 Witcher 在实际的网络应用上的性能,我们进行了第二次对比评估,使用了 OpenEMR 版本 5.0.1.7。我们使用 Reqr 来识别应用程序的 URL 和输入变量。
接下来,Witcher 对每个 URL 进行了五次独立的试验,使用了每个配置。我们排除了 AFLR,因为在微型测试评估中它的表现较差;因此,我们评估了剩下的三个配置:AFLHR、WiCR 和 WiCHR。我们在每次试验开始时初始化了数据库和会话,以帮助保持试验之间的一致性。
为了进行评估,我们收集了 PHP 代码覆盖率数据,用于进行 Mann-Whitney 检验。我们使用 PHP 扩展 Xdebug 提取 PHP 代码覆盖信息 [36]。接下来,我们计算了使用特定配置和试验的所有脚本的总代码行数。有了总代码行数,我们可以使用每次试验的结果来比较不同的配置。
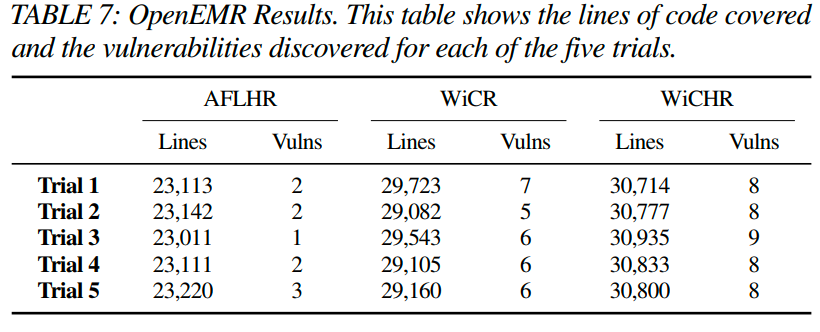
附录中的表 7 显示了结果:每次试验中使用不同配置达到的代码总行数。WiCHR 一直执行的代码行数最多,其次是 WiCR,然后是 AFLHR。特性集之间性能差异是统计学意义的:Mann-Whitney U 检验的 p 值为 0.01208。
表 7 还显示了每个试验和配置发现的漏洞。所有的特性集在每次试验中都发现了漏洞;然而,WiCR 和 WiCHR 的表现明显优于 AFLHR。WiCHR 在每次试验中发现了最多的漏洞。
5.2. Witcher Evaluation
根据第 5.1 节中所示的特性比较结果,我们选择了 WiCHR 配置来将 Witcher 与其他网络扫描工具进行比较。我们使用了一个多样的数据集作为评估数据集,其中包含了不同语言编写并在不同平台上运行的各种网络应用:其中一些具有已知的漏洞,而另一些则是经过更新且没有已知注入漏洞的应用。在这次评估中,我们通过验证漏洞是否可利用来手动确认每个漏洞。
除了有趣的漏洞外,其余的命令和 SQL 注入漏洞都是严重的,因为它们使攻击者能够破坏、修改和窃取数据 [37]。对于命令注入漏洞,我们验证了应用程序是否执行了任意 shell 命令。对于 SQL 注入漏洞,我们通过将 Witcher 的崩溃信息提供给 SQLMap 来自动利用这些漏洞,从而完全控制数据库或执行任意 SQL 函数。
对于已知的易受攻击应用,我们使用了一组包括八个 PHP 应用、五个固件镜像(源代码可能是 C 语言编写,平台为 ARM、MIPSEL 和 MIPSEB)、一个 Java 应用、一个 Python 应用以及一个 Node.js 应用,总共包含 36 个已知漏洞。我们搜索了具有工作漏洞利用程序的 SQL 注入和命令注入漏洞的公开 CVE(常见漏洞及暴露)信息(以便验证漏洞的存在性),从中获得了 Doctor Appointment、Login Management、Hospital Management 和 rConfig 这几个相关的应用。我们选择了 WackoPicko、OpenEMR 和 Juice Shop,因为它们具有已知的漏洞,并且在先前的研究中使用过(有关使用相同网络应用进行评估的先前研究,请参见附录中的表 10)。
我们还选择了五个固件目标,以展示 Witcher 在非解释型网络应用上的模糊能力。我们选择了 D-Link 的 825、823G 版本 1.0.2B03、823G 版本 1.0.2B05 和 645,以及 Tenda AC9,因为这些固件的 Web 服务器在 QEMU 模拟器中运行,它们各自具有已知的 CVE,而且这些 CVE 包括了工作的漏洞利用脚本。表 6 显示了所有应用程序中已知的漏洞,以及 CVE 编号(如果已知)和漏洞类型。
我们还选择了用于先前研究评估的最新版本的网络应用,以确保 Witcher 能够对最新版本的网络应用进行模糊测试。特别地,我们选择了 phpBB、osCommerce 和 WordPress,每个应用都在四个或更多的先前论文中进行了评估,此外,我们还添加了一个基于 Ruby on Rails 的 Web 应用 Thredded。
在此评估中使用的这 18 个网络应用程序的名称总结在附录的表 10 中,同时还包括了网络应用程序的语言或平台、已知测试版本的发布日期(最早的版本发布于 2014 年)、版本号、GitHub 上的星标数量(作为估计网络应用程序受欢迎程度的指标)、自定义 Google Dork 的搜索结果数量(如果网络应用程序的源代码不在 GitHub 上,这是估计实际使用情况的另一种方式)、应用程序的代码行数,以及此网络应用程序是否在先前的研究中使用过。
为了运行这次评估,我们为每个网络应用程序创建了 Docker 容器,启动了网络应用程序,并运行了 Witcher。Witcher 的配置包括入口 URL、登录页面的识别、相关的凭据,以及表单字段的选择器。我们限制了 Witcher 的爬虫运行时间为四个小时,而将每个 URL 与两个或更多的输入变量一起模糊测试了 20 分钟。因此,总的运行时间因爬虫识别到的端点数量而异。
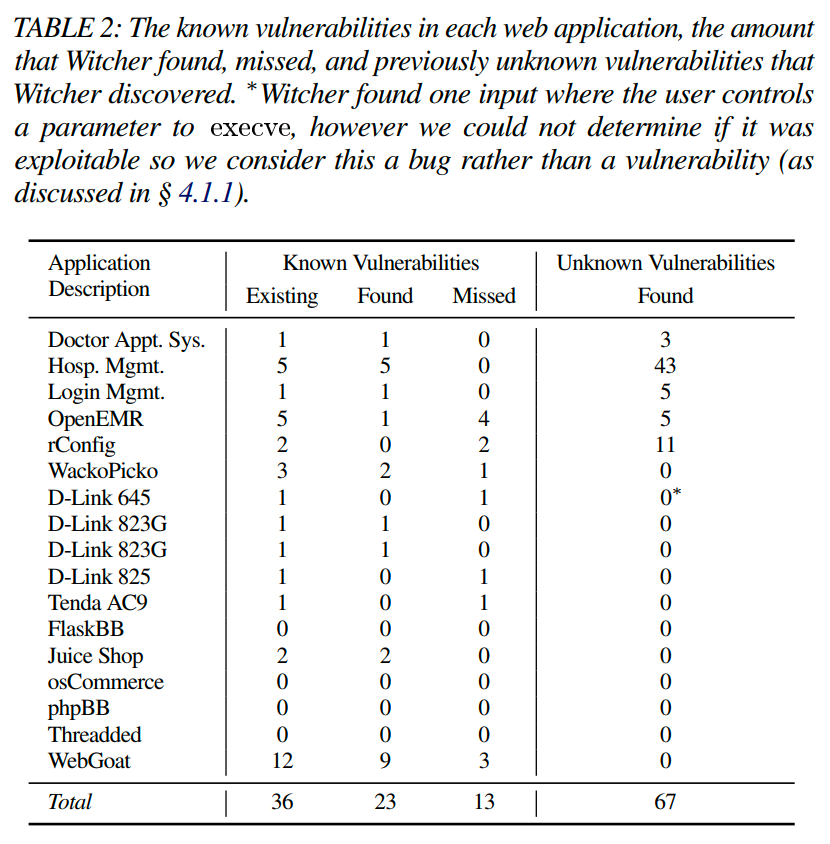
这次评估的结果概览如表 2 所示。Witcher 成功地爬取和模糊测试了所有的网络应用程序,最终发现了总共 90 个独特的漏洞,其中 67 个是先前未知的。所有发现的漏洞都来自已知存在漏洞的网络应用程序(也就是说,Witcher 没有在最新版本的 Thredded、phpBB、osCommerce 或 WordPress 中发现先前未知的漏洞)。Witcher 发现了 36 个已知漏洞中的 23 个(63.9%);然而,Witcher 未发现 13 个(36.1%)漏洞。表 6 显示了哪些已知漏洞被发现或未发现的详细结果,以及简要说明原因。特别地,有八个漏洞未被发现,因为爬虫无法找到对应的 URL。某些 URL 没有被爬虫发现,是因为应用程序需要特定的一系列步骤,比如在 OpenEMR 中选择患者(这是探索有状态网络应用程序的已知问题[20],[14])。当 URL 没有包含在网络应用程序的用户界面中时,爬虫也会错过这些 URL,比如 Tenda AC9 固件中的后门 URL。在 WebGoat 应用程序中,爬虫由于实现中的一个错误而错过了两个漏洞,导致 Web 服务器意外崩溃,另一个漏洞是因为 HTTP harness 目前不支持 HTTP PUT 方法。动态分析工具的误报率通常较高,然而 Witcher 的误报率为 36.1%,低于其他出版物中报告的 47% [38] 和 60% [21]。
正如表 2 所示,Witcher 发现了 67 个先前未知的漏洞(65 个 SQL 注入和 2 个命令注入)。虽然我们计划负责地公开还相关且未被发现的独特漏洞,但我们已经收到了关于 OpenEMR SQL 漏洞的未发布 CVE:CVE-2020-11754、CVE-2020-11755、CVE-2020-11756 和 CVE-2020-11757。
除了 Witcher 报告的漏洞外,Witcher 还报告了两个误报和三个错误。然而,这些错误是有趣的,因为它们展示了使用高熵输入来测试网络应用程序的潜力。
5.3. Grey-box and black-box comparison
在第5.2节中,我们评估了Witcher在识别网络应用程序漏洞方面的有效性。现在我们将比较Witcher,即一种灰盒式网络应用程序漏洞模糊测试工具,与最先进的商业黑盒式网络应用程序漏洞扫描工具Burp [5]、数据驱动的网络应用程序爬虫Black Widow [14]以及最近发布的灰盒式爬虫和模糊测试工具WebFuzz [10]。我们选择Black Widow和WebFuzz扫描工具是因为它们的新近性和性能。例如,Black Widow在与其他六个开源网络漏洞扫描工具(Arachni [39]、Enemy of the State [40]、Skipfish [41]、jÄk [42]、w3af [43]和ZAP [8])的比较中表现出色。尽管我们本来希望比较Witcher与BackREST的NodeJS模糊测试能力,但由于专利问题,作者无法共享该工具[9]。我们将评估范围限制在了九个使用PHP编写的应用程序上(在表10中列出),以便我们可以使用第5.1.2节中描述的方法收集代码覆盖率数据。
Burp Evaluation. 了与Burp比较我们的方法,我们评估了目标网络应用程序的多少代码被执行以及发现了多少漏洞。由于Burp有自己的爬行组件,我们在两种不同的配置下与Burp进行比较:(1)没有更改的Burp(独立版),其中Burp自己爬行了网络应用程序,(2)Burp与Witcher相结合,我们将从Witcher的爬虫中派生的请求提供给Burp。因此,BurpPlus Witcher和Witcher之间的结果比较与爬虫之间的差异无关,而是与为应用程序生成的输入差异有关。
我们为Burp(独立版)和BurpPlus Witcher配置了相同的扫描方式。在配置每个扫描时,我们选择了内置的配置,以获得最完整的爬行和最大的审计覆盖,并且最完整的爬行默认限制为五个小时。Burp的审计(即发现漏洞)没有超时选项,并且会一直运行直至完成。
Burp与Witcher之间的一个差异在于,Burp会轮换URL,并且不会同时专注于一个单一的目标URL,相反,它会多次移动所有URL,这增加了由另一页引起的状态变化导致发现网络应用程序的新部分的可能性。然而,Witcher每次专注于单个页面,这意味着它不太可能触发多页状态。
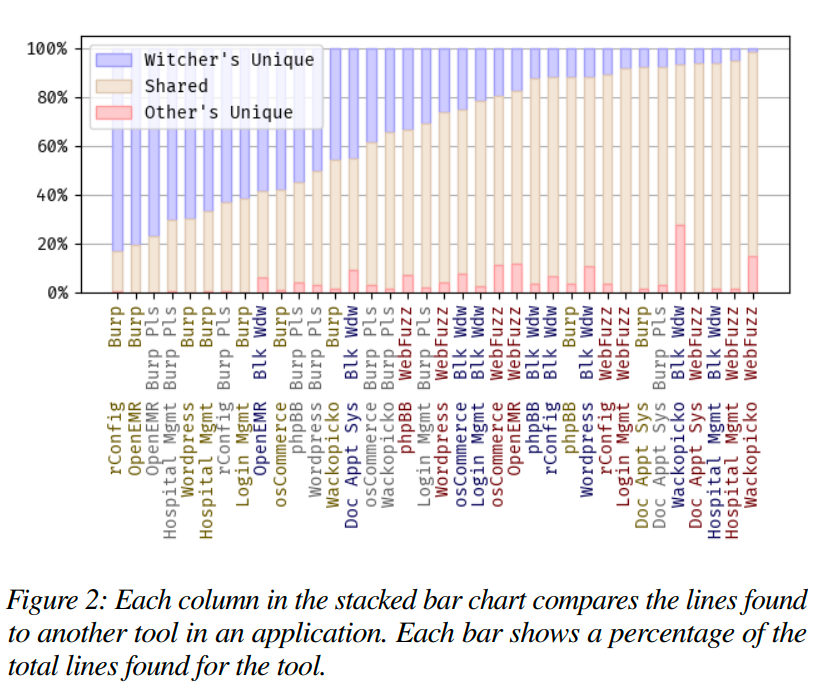
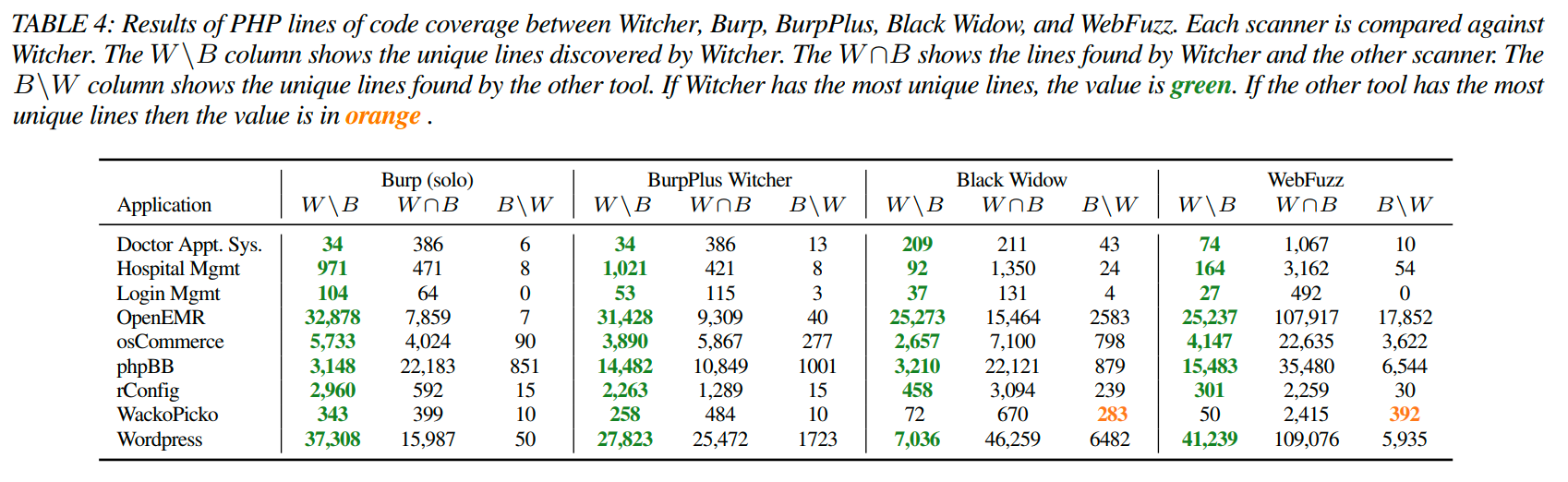
我们将这个实验的结果总结在表4和图2中。在代码覆盖结果中,Witcher在每个应用程序中执行的代码行数都超过了Burp(独立版)和BurpPlus Witcher。Witcher为四个应用程序的代码覆盖率增加了100%以上。一个令人惊讶的结果是phpBB测试用例,在这个实验中,BurpPlus Witcher的代码覆盖率比Burp(独立版)差了52.3%。这是唯一一个BurpPlus Witcher达到爬行超时阈值的实验。因此,BurpPlus Witcher的终端点较少,导致覆盖的代码行数较少。
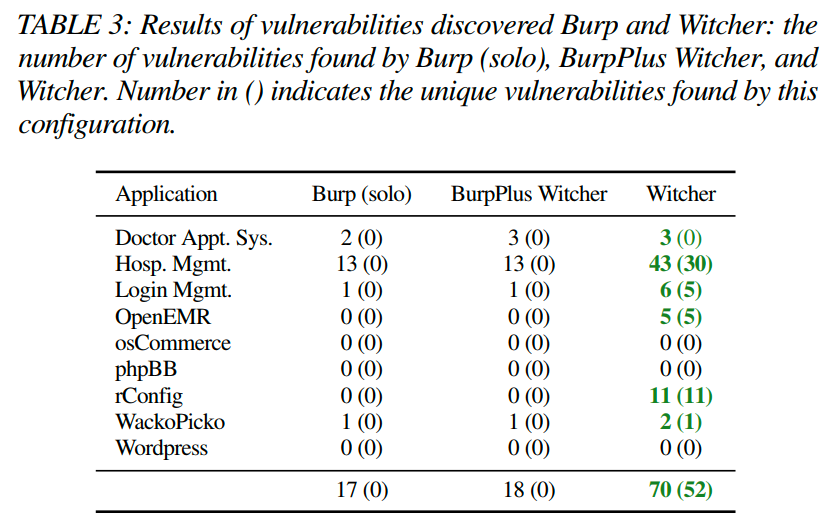
如表3中的漏洞结果所示,Witcher发现了70个漏洞,其中52个在三个配置之间是唯一的。Witcher在九个应用程序中的六个应用程序中发现了最多的漏洞。
Black Widow and WebFuzz Evaluation. 对于Black Widow和WebFuzz的评估,我们只比较了执行的唯一代码行数,因为Black Widow和WebFuzz针对XSS漏洞,而Witcher则针对SQL和命令注入漏洞。我们使用Witcher在爬行阶段发现的HTTP请求来初始化WebFuzz,以便在评估中专注于模糊测试工具。由于Black Widow的爬虫性质,我们无法使用相同的种子来初始化Black Widow。但是,我们添加了用户名和密码参数,以便Black Widow使用现有帐户。
Black Widow和WebFuzz在测试Web应用程序时交织执行不同的页面。通过交织执行,这些工具可以触发并模糊依赖于两个网页之间相互关联的新应用程序状态。例如,工具可能会在产品页面上向购物车添加商品,并在购物车页面上进行结算。目前,Witcher一次只关注一个页面,因此不太可能触发这些相互依赖的状态。此外,Black Widow使用状态监控来发现新的应用程序状态。
Witcher的速度和突变策略在URL交织和状态监控方面表现出色。如表4和图2所示,在除了WackoPicko之外的所有应用程序上,Witcher都通过发现更多的唯一代码行数而胜过了Black Widow和WebFuzz。在WackoPicko上,这些工具在购物车功能中找到了额外的代码行数。通过交织爬行和模糊测试,这些工具能够在购物车中引发一个新状态,从而暴露出一个原本隐藏的URL。
**Vulnerability Target Bias. ** 在接下来的评估中,我们测试了不同的漏洞目标是否可能在评估中引入了结果改变的偏差,从而在之前的代码覆盖率评估中不公平地使Witcher受益。Black Widow和WebFuzz的目标是XSS漏洞,而Witcher的目标是SQL和命令注入漏洞。Black Widow和WebFuzz会形成有效的预定义XSS有效负载来检测XSS漏洞。尽管Witcher不生成攻击有效负载 - 它输入随机字节并交换可能触发故障升级的变量 - 但我们无法保证隐式的命令和SQL注入假设不会影响Witcher。因此,这些不同的有效负载和假设可能引入了覆盖率偏差,使工具之间的比较不太等效。
为了评估偏差,我们采用了“Enemy of the State” [20]中的一种方法,其中他们将w3af测试组件添加到了状态感知爬虫中,以控制漏洞检测。在我们的评估中,我们通过将Black Widow和WebFuzz的代码覆盖率与BurpPlus的代码覆盖率相结合(仅启用SQL审计,并将Witcher的URL加载到Burp中)来模拟相同的控制情况。将BurpPlus的仅SQL结果与Black Widow和WebFuzz相结合不会改变与Witcher的任何比较结果,从而降低了不同的漏洞目标不公平地使Witcher受益的可能性。在表5中,BurpPlus为这些扫描器的大多数Web应用程序添加了覆盖的行数。然而,这些额外的行数并未改变比较结果的结果。此外,所有应用程序的百分比增加量(变化量/总行数覆盖率)都小于3.3%(参见表11)。因此,对于选择的Web应用程序,漏洞目标偏差不太可能影响结果。
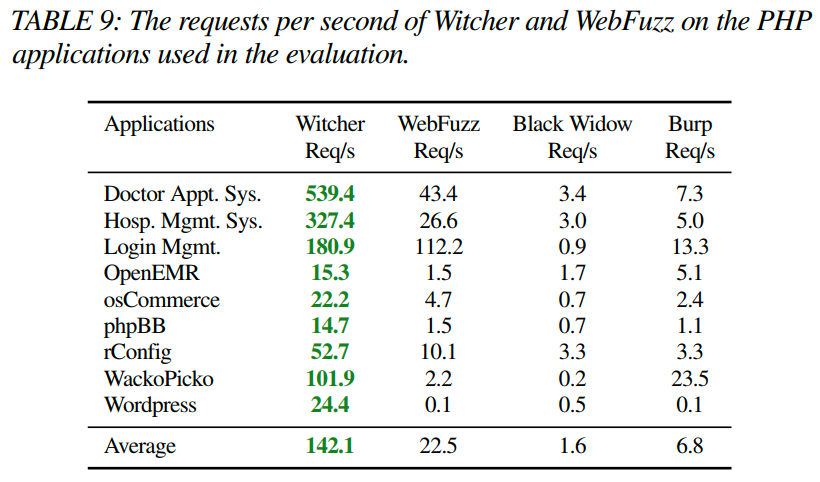
Performance. 为了了解性能成本,即每秒请求数,我们比较了Witcher、WebFuzz、Black Widow和Burp的每秒请求数。在评估中,我们对每个PHP Web应用程序分别在Witcher(一个核心)、Burp(最多十个并发请求)、WebFuzz(单个工作者)和Black Widow(一个核心)上执行了八个小时。 附录中的表9显示,Witcher对每个Web应用程序发送的请求数量最多。Witcher的平均每秒请求次数为142.1,而WebFuzz的平均每秒请求数为22.5,Black Widow的平均每秒请求数为1.6,Burp的平均每秒请求数为6.8。虽然Witcher在代码覆盖方面表现出色,但其发出的请求数量是次快速工具的六倍;然而,覆盖率并没有提高六倍。因此,通过应用混合方法,Witcher可能会在请求每秒的潜在成本的情况下改善覆盖率。
6. Discussion
略
本文作者:Du4t
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!