目录
🤔
CarpetFuzz: Automatic Program Option Constraint Extraction from Documentation for Fuzzing
Abstract
软件中的大规模代码支持丰富多样的功能,同时也包含潜在的漏洞。作为最流行的漏洞检测方法之一,模糊测试在工业界和学术界不断发展,旨在通过覆盖更多的代码来发现更多的漏洞。然而,我们发现即使使用最先进的模糊测试工具,仍然存在一些未开发的代码,只能通过特定的程序选项组合来触发。简单地变异选项可能会产生许多无效的组合,因为没有考虑选项之间的约束关系。本文中,我们利用自然语言处理(NLP)从程序文档中自动提取选项描述,并分析选项之间的关系(例如冲突、依赖关系),以过滤掉无效的组合,仅留下有效的组合进行模糊测试。我们实现了一个名为CarpetFuzz的工具,并评估了其性能。结果显示,CarpetFuzz能够准确提取文档中的关系,精确度为96.10%,召回率为88.85%。基于这些关系,CarpetFuzz将待测试的选项组合减少了67.91%。它帮助AFL找到其他模糊测试工具无法发现的路径增加了45.97%。经过对20个流行的开源程序的分析,CarpetFuzz发现了57个漏洞,其中包括43个未公开的漏洞。我们还成功获得了30个漏洞的CVE编号。
1 Introduction
件复杂性的增加,软件中的代码规模迅速增长。例如,根据OpenHub的分析报告[36, 37],流行软件Apache HTTP Server和MySQL的代码行数分别达到了160万和290万。大规模的代码支持软件的丰富多样的功能,满足用户的各种需求。然而,它也扩大了攻击面,并增加了发现潜在漏洞的难度,带来更高的安全风险和防御成本。
覆盖率导向的模糊测试是最成功的漏洞发现技术之一[69],它通过变异输入来增加代码覆盖率,以触发软件中的潜在安全违规(例如写访问冲突)。大多数以前的研究都集中在优化模糊测试过程中的策略,以增加覆盖率,例如种子选择[20,41]、种子调度[3,4,40,54,61,67]、变异[8,32]和反馈策略[1,6,15,16,30,33,44]。这些改进显著提升了模糊测试工具发现漏洞的能力。截至2022年1月,仅Google的持续模糊测试服务OSS-Fuzz已经发现了超过36,000个漏洞[19]。然而,尽管最新的模糊测试工具使用不同的策略选择各种种子并对输入进行变异,并且已经具备了强大的程序探索能力,但仍然存在一些未被探索的代码。
主要原因是这些最新的模糊测试工具没有对具有特定命令行选项的程序进行模糊测试。命令行选项(或简称选项)告诉程序要修改哪个操作。某些选项对应不同的程序分支,意味着只有通过指定特定选项才能访问到某些代码,而不能通过改变输入文件来实现。然而,在先前暴露的漏洞中,只有少部分选项被指定。例如,Libtiff在2014年至2020年期间的103个CVE漏洞只包括了20个不同的选项,仅占总选项的9.8%,这意味着许多依赖于选项的代码可能仍未被探索。由于组合的数量可能很大,无法对它们进行全部迭代。例如,流行的图像处理程序ImageMagick有242个不同的选项[23],共有7.1×1072种可能的组合。
一些研究人员[5, 9, 29, 45, 55, 66]尝试通过变异选项组合来解决这个限制。然而,许多变异的组合可能是无效的,因为它们没有考虑选项之间的关系,比如冲突(即不能同时使用)和依赖关系(即必须同时使用)。例如,先前研究中使用变异算法生成的openssl-rsa选项组合中,只有11%是有效的。本文旨在提取选项之间的关系,但由于以下原因具有挑战性。
Challenge - C1. 选项之间的关系通常以自然语言的形式在文档中声明,并且可以以完全不同的方式声明,这大大增加了识别的难度。例如,选项-a和-b之间的冲突可以用多种方式声明,如“-a不能与-b一起使用”、“-a与-b互斥”和“只能给出这些选项中的一个”。简单的方法,如模板匹配,在这个问题上效果不好。此外,某些关系是隐含声明的,只能通过比较多个句子来确定。例如,tiffcp文档将-B和-L选项描述为“强制输出使用大端字节顺序写入”和“强制输出使用小端字节顺序写入”。虽然没有明确声明,但通过比较这两个句子可以推断出-B和-L之间的冲突,因为它们描述了两种截然相反的行为。识别这些关系的一种准确而直接的方法是手动检查,但这对于大规模的识别来说既费时又不切实际。如何从文档中自动找出选项之间的关系变得必要。
Challenge - C2. 一旦从文档中识别出自然语言形式的关系,自动提取具体的关系(如冲突或依赖关系)仍然很困难。首先,自动定位关系涉及的选项是具有挑战性的。例如,句子“-f或-b必须与-C一起使用,而-C不能与-F或-d一起使用”声明了-f、-b和-C选项之间的依赖关系,以及-C、-F和-d选项之间的冲突关系。如果没有对语法结构进行准确分析,这些关系相关的选项无法自动确定。其次,如前所述,选项之间的关系可以以完全不同的方式声明。因此,简单的关键词匹配等方法无法用于确定自动声明的关系类型。
在这篇论文中,我们解决了上述挑战,并提出了一种名为CarpetFuzz的基于自然语言处理(NLP)的模糊测试辅助工具,用于提取程序选项约束。CarpetFuzz的基本思想是利用自然语言处理技术从文档中的每个选项描述中识别和提取程序选项之间的关系(例如冲突或依赖关系),并过滤掉无效的组合,以减少需要进行模糊测试的选项组合数量。
给定一个程序的文档,CarpetFuzz首先通过解析“OPTIONS”部分提取出所有选项及其对应的描述。然后,CarpetFuzz使用一个机器学习模型来确定描述中是否声明了关系。由于此类句子在文档中所占比例很小(例如,在tiffcp文档中仅占3.4%),我们使用基于信息熵的不确定性采样方法(一种有效的主动学习方法)来减少标记训练数据的人力工作量。为了识别多个句子隐含声明的关系,CarpetFuzz对隐含声明的一系列特征进行总结,并利用NLP找到满足这些特征的所有句子对。在确定程序选项之间的关系后,CarpetFuzz利用混合正向和反向遍历的方法从依赖树中(通过依赖解析得到)找到与关系相关的节点。此外,基于语言学,CarpetFuzz利用基于极性的有限状态机来确定具体的关系。最后,CarpetFuzz过滤掉不满足这些关系的组合,以减少用于模糊测试的组合数量。
我们对20个流行的开源程序进行了CarpetFuzz的评估。根据它们的文档,CarpetFuzz在260.8秒内从文档中提取了282个关系,其中包括2952个句子,精确度为96.10%,召回率为88.85%。其中,218个关系是隐含声明的,精确度为95.87%,召回率为90.09%。基于这些关系,我们减少了67.91%的选项组合,显著降低了组合搜索空间,证明了提取选项关系的必要性。通过有效的选项组合,CarpetFuzz帮助AFL发现了其他模糊测试工具无法发现的路径的数量增加了45.97%。此外,CarpetFuzz还发现了57个崩溃。经过我们的分析,其中30个崩溃与特定的选项组合相关,证明了使用有效选项组合进行模糊测试的重要性。目前,有30个崩溃已被分配了CVE ID。我们还将CarpetFuzz与最新的选项配置模糊测试工具POWER在其基准上进行了性能比较。CarpetFuzz发现了94个独特的崩溃,是POWER的1.71倍。
**Responsible disclosure. ** 我们在发现这些漏洞后立即将其披露给软件开发者。此外,我们积极主动地向他们提供了补丁。到目前为止,已修复了45个漏洞,其中9个通过我们的补丁进行修复。
**Contributions. ** 本论文的贡献总结如下:
- 我们提出了一种新的技术,用于从文档中识别和提取程序选项之间的约束关系。据我们所知,这是第一项尝试使用自然语言处理(NLP)来自动确定文档中程序选项之间关系的研究。借助这种技术,AFL能够发现其他模糊测试工具无法发现的路径增加了45.97%。
- 我们实现了原型工具CarpetFuzz,并在20个受欢迎的真实世界开源程序上进行了评估。CarpetFuzz准确地从文档中提取了88.85%的关系。通过使用CarpetFuzz获取的有效选项组合对这些程序进行模糊测试,我们发现了57个独特的崩溃情况,其中30个已被分配CVE编号。
- 为了促进该领域的研究,我们将我们的原型工具和数据集开源。
2 Background and Related Work
2.1 Coverage-Guided Fuzzing
覆盖率引导的模糊测试是一种利用程序插桩获得的代码覆盖信息来指导模糊测试过程的技术。与传统的黑盒模糊测试技术类似,覆盖率引导的模糊测试技术通过不断变异输入来尝试在目标程序中触发异常,但由于有了覆盖信息,它具有更有效的变异过程。覆盖率引导的模糊测试过程如图1所示。为了开始覆盖率引导的模糊测试,用户需要指定选项(在命令行中)和种子文件(步骤1)。选项以常量形式存储在配置中,在整个模糊测试过程中不会改变。种子文件被传入输入队列,然后发送到变异引擎以更改其内容(步骤2)。变异后,执行引擎从配置中读取执行命令,并用变异后的文件替换输入以检查其覆盖率(步骤3)。如果变异后的文件激活了新的覆盖率(即有趣的覆盖率),则将将此变异文件添加到输入队列进行进一步的变异(步骤4)。

许多研究都致力于通过修改种子选择[20, 41]、种子调度[3, 4, 8, 32, 40, 54, 61, 67]和反馈策略[1, 6, 15, 16, 30, 33, 44]来改进基于覆盖率的模糊测试。其中,Rebert等人[41]提出了六种种子选择方法,并将问题形式化为集合覆盖和整数线性规划。Böhme等人[4]使用马尔可夫链模型对覆盖率引导的模糊测试过程进行了形式化,并通过增加低频路径种子的变异次数来加速该过程。Chen等人[6]提出了一种细粒度的反馈度量方法,利用字节级污点跟踪确定与分支相关的字节。这些工作显著提高了模糊测试的效率,并增加了模糊测试过程中的覆盖率。然而,在我们的测试中,这些模糊测试工具无法触达与选项相关的路径。
2.2 Option and Combination
命令行选项是用户在程序启动时指定的信息项,用于告诉程序要启用或禁用哪些操作[58]。一个程序通常有多个选项,在命令行中紧跟程序名称,并用空格分隔。例如,tiffcp和pdftops分别有20个和34个选项。借助这些选项,用户可以将自己的需求传递给程序,以便它能够按照他们的意愿执行相应操作。
当需求变得复杂时,用户需要同时指定多个选项来替代使用少数选项。然而,并非所有的组合都是有效的,这是因为选项之间存在关系(例如冲突和依赖关系)。一个无效的组合可能会导致程序在早期阶段抛出异常并退出。为了防止用户使用无效的组合,开发人员通常在文档中以自然语言的形式注明选项之间的关系,例如"仅在指定了 -p 选项时有效",以及" -level1 选项不能与 -form 一起使用"。
为此,一些研究通过组合选项(或称为选项配置)来寻找无法到达的路径。AFLargv [5] 在命令行选项的数量和大小的上下界内对选项配置进行变异。Wang等人[55]将选项感知模糊测试应用于有向灰盒模糊测试,通过搜索选项配置来到达无法到达的目标位置。Song等人[45]提出了一种新的覆盖反馈度量,即有效对,用于预测解析器是否拒绝输入以检查执行的有效性。Zeller等人[64]设计了一个工具,基于特定的选项解析模块(例如C中的getopt函数),自动推断源代码中的选项配置。POWER [29]利用三种变异操作来探索选项配置。然而,由于大多数方法缺乏对选项之间约束的考虑,生成的许多组合可能是无效的,降低了搜索效率。ConfigFuzz [66]考虑了这些约束,但依赖于手动检查。尽管从文档中提取选项之间的约束可能是一项一次性的工作,但需要测试人员深入了解目标程序,这是不可承受的,特别是在进行大规模测试(例如成千上万个应用程序)时。受到这一发现的启发,我们研究了从文档中自动提取约束以过滤无效的选项组合。
2.3 NLP-based vulnerability discovery.
先前的研究还尝试基于自然语言处理(NLP)发现漏洞,主要是从代码注释[17, 48–50, 59, 65]和文档[31,38,68]中找出程序的约束,以辅助进行静态分析。此外,Xie等人[60]尝试从文档中提取信息,用于指导对深度学习(DL)库进行模糊测试。然而,这项工作只适用于API库,而不适用于可执行程序。此外,它依赖于严格格式的文档(即DL文档),无法用于解析格式较松散的文档,如man页面。与先前的工作不同,我们尝试利用NLP解析格式较松散的文档,并从文档中提取约束以过滤无效的选项组合,以辅助进行模糊测试。
3 Design
在这一部分,我们介绍了CarpetFuzz的设计,这是一个基于NLP的模糊测试辅助工具,用于提取程序选项的约束。核心思想是利用NLP从文档中每个选项的描述中识别和提取程序选项之间的关系(例如冲突或依赖关系),并过滤掉无效的组合,以减少需要进行模糊测试的选项组合数量。我们首先概述了整体设计的概况,然后介绍了每个组件的工作原理。
3.1 Overview
图2展示了CarpetFuzz的概览。给定目标程序的文档,CarpetFuzz首先通过解析OPTIONS部分提取所有选项及其相应的描述,并使用NLP工具将这些描述拆分为句子(步骤1)。然后,CarpetFuzz识别包含这些选项之间关系的句子(称为R句子)(步骤2)。具体而言,CarpetFuzz利用主动学习算法从Linux manpages构建数据集,并训练机器学习模型来识别明确声明的关系。为了找到隐含的关系,CarpetFuzz结合了NLP解析技术(依存句法分析和组成句法分析)与启发式规则。在识别R句子后,CarpetFuzz利用依存句法分析构建这些R句子的依存树,并从选项所在节点遍历依存树以提取具体的关系和对象(步骤3)。利用提取出的关系,CarpetFuzz构建有效的选项组合,并按照覆盖率对它们进行优先级排序(步骤4)。最后,CarpetFuzz将这些优先级排序的有效选项组合传递给模糊测试工具。
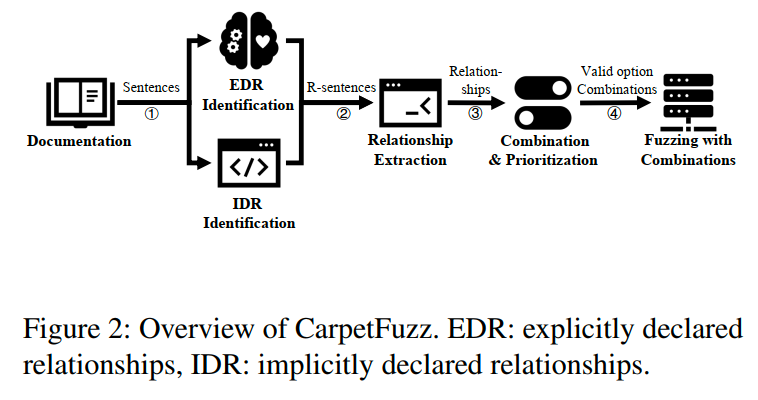
3.2 Explicitly Declared Relationship Identification
在分析了大量文档后,我们发现选项之间明确声明的关系主要可以分为五类,包括冲突、依赖、蕴含、相似性和替代关系(附录A)。选项之间的冲突表示这些选项不能同时使用,而选项之间的依赖表示这些选项必须同时使用。蕴含表示一个选项的功能包含另一个选项。相似性和替代关系表示选项的功能大致相同和可以相互替代。所有这三种关系都表示多个选项之间存在重叠的功能。尽管这三种关系的选项组合可能不会引起异常,但会使一些选项被覆盖。使用这些选项组合进行模糊测试可能与单独测试每个选项产生相同的效果,对于发现新路径可能是无用的。为了避免这种无用的组合并减少搜索空间,我们在本文中将这三种关系视为冲突关系。
我们从互联网收集了大量文档,并提取了所有选项描述中的句子作为无标签数据集。为了降低标注成本,我们使用主动学习算法手动标注了无标签数据集中一部分样本,并将它们添加到带标签的数据集中。具体而言,我们首先阅读了一小部分文档,并手动收集了多个R句子的关键词(约20个),例如“combine with”、“imply”、“like”、“ignore”,这是一个一次性的小任务(约5分钟)。需要注意的是,虽然这些关键词来自于少量文档,但它们也适用于其他文档,并且可以通过主动学习中的数据标注进行系统扩充。然后,我们对包含这些关键词的句子进行采样,进行手动标注,这组成了我们模型的初始训练数据集。具有五种关系中的句子被标记为正例,其他句子被标记为负例。通常情况下,数百个带标签的数据足以训练初始模型,与数据集的大小无关。我们利用word2vec模型[42]将单词映射为向量作为输入特征,因为它简单且成本较低。我们还评估了更高级的模型(如BERT [13])并获得了类似的性能。在主动学习算法的每次迭代中,使用机器学习模型获取无标签数据集中所有样本的预测结果,并根据基于熵的不确定性采样算法[11]选择样本进行手动标注。
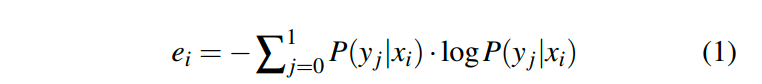
在公式中,表示第i个无标签样本的熵,表示属于类别1(是R句子)的预测概率,表示属于类别0(不是R句子)的预测概率。熵越高,代表模型对样本的预测结果越不确定。因此,对这些样本进行标注有助于更有效地更新模型。选择熵最高的K个样本进行手动标注,并将它们添加到训练集中,然后使用更新后的训练集重新训练模型(附录B)。经过T次迭代后,最终模型将用于显式声明的关系识别。特别地,在主动学习过程中,我们对1,381个句子进行了手动标注(其中557个为正例,824个为负例),这仅占所有无标签句子的0.46%。需要注意的是,数据标注是一次性的工作(仅在训练过程中进行,约5小时),后续的测试不需要人力投入。我们从剩余的无标签数据集中随机抽样了1,000个数据进行评估,最终模型的准确率、误报率和召回率分别为92.90%、11.49%和98.42%。
3.3 Implicitly Declared Relationship Identification
正如介绍中所提到的,隐式声明的关系是很具挑战性的。这些关系涉及多个选项,它们的行为是不同但相关的,并且只有在找到关联时才能识别出来。经过分析大量程序文档,我们只发现了隐式声明的冲突(尚未找到隐式声明的依赖关系)。在本文中,我们只讨论隐式声明冲突的识别。
我们发现,隐式声明不同选项之间冲突的句子(即隐式R句子)通常具有相同的对象和相同/反义动词,这意味着这些选项在同一个对象上做相同(或相反)的事情。它们的语法结构通常满足平行结构(即在几个部分中重复相同的语法形式),这可能是因为文档作者为了方便而为每个冲突选项复制了描述。例如,-B和-L选项的描述分别是“强制使用大端字节顺序编写输出”和“强制使用小端字节顺序编写输出”。由于这两个句子具有相同的谓词(即force)、对象(即output)和语法结构(解析树),我们可以确定它们是隐式的R句子。
要确定多个句子是否是隐式的R句子,我们需要提取它们描述中的对象、谓词和解析树。图3展示了提取这些特征的过程。首先,我们对描述进行预处理(步骤1),通过提取每个描述的第一句话进行分析,因为这样的句子通常是介绍选项功能的主题句。我们发现,某些选项的主题句可能没有主语(以动词开始),这会导致自然语言处理器出现错误,例如误将动词"force"误判为名词。因此,对于以动词开头的句子,我们会恢复其主语(即it)并修改动词的人称,以避免解析错误。例如,在tiffcp中,-B选项的描述“Force output to be written with Big-Endian byte order”将被修改为“It forces output to be written with Big-Endian byte order”。
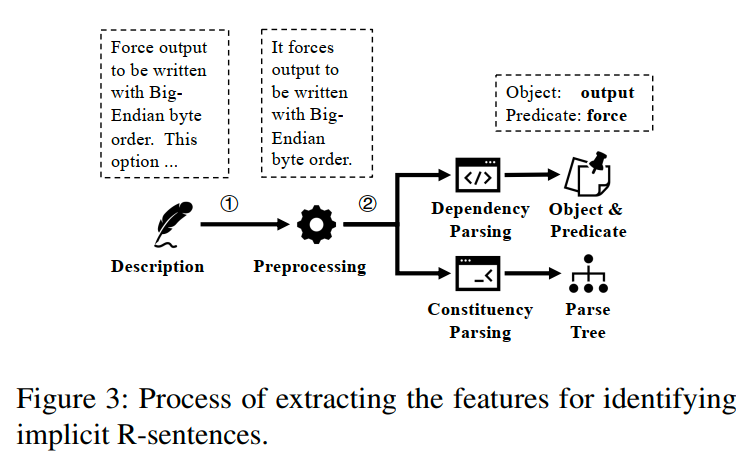
在预处理之后,句子将进行依存分析以找到谓词和直接宾语(步骤2)。具体而言,我们使用自然语言处理工具标记每个单词的依存关系,并找到具有“dobj”(即直接宾语)和“ROOT”(即谓词)标签的单词。为了确定这两个句子是否具有平行结构,我们使用短语结构分析构建它们的解析树,并删除叶子节点,因为叶子节点代表具体的单词而不是语法结构。如果它们的长度相同,并且剩余的树完全相同,我们认为它们具有平行结构。如果它们的长度不同,我们首先从较短的树的最后一个节点开始遍历,找到其最近的分支节点,然后删除该分支节点及其所有子节点。如果剩余的树是较长树的子树,我们认为这两个树具有平行结构。最后,当多个句子具有相同的对象、相同或互为反义词的谓词,并且具有平行结构的解析树时,我们将其视为隐式的R句子。
此外,在某些文档中,多个选项会一起写在同一个位置,这是另一种隐式声明的冲突。例如,在openssl-ec中,-des、-des3和-idea选项被一起写为“-des|-des3|-idea”,如图4所示。然而,一起写的选项不一定冲突,它们可能是同一个选项的别名。例如,虽然-s和--silent选项被一起写为“-s, --silent”,但它们并不冲突,而是表示同一个选项。我们可以通过检查共享多个选项的主题句的主语来确定它是否是隐式的R句子。当主语是复数形式(例如,“they”或“these options”)时,意味着这个句子是隐式的R句子。

总的来说,我们从20个流行的程序文档中发现了218对隐式声明的冲突。其中,准确率为95.87%,召回率为90.09%。
3.4 Relationship Extraction
在从文档中找出R句子之后,我们需要从这些句子中提取具体的关系,包括冲突和依赖关系(正如在第3.2节中提到的那样,暗示、相似性和替代性也被视为冲突)。
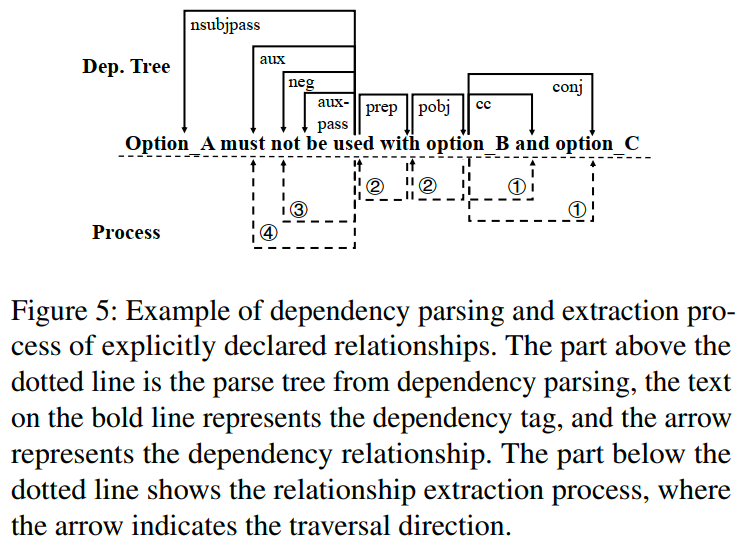
提取显式声明的关系。对于显式声明关系的R句子,我们首先使用组成分析将复杂的句子分为多个从句。如果从句中包含选项,我们将它们的名称替换为自定义符号(例如,option_A),以避免减号干扰解析过程。然后,我们使用依存解析获得该从句的句法树。图5展示了基于句法树的显式声明关系的提取过程。首先,我们确定第一个选项出现的位置,然后向前遍历句法树,查看是否有其他选项与第一个选项存在共依赖关系(即,“conj”标签)。由于R句子可能包含其他程序的选项,我们在分析之前检查定位到的选项是否属于目标程序。我们将具有共依赖关系的选项视为单个选项,并确认并列关系(即,“cc”标签)。对于没有共依赖关系的选项,我们单独进行关系抽取过程。其次,我们从选项的位置开始向后遍历句法树,寻找与选项相关的动词或形容词(即,“pobj”和“prep”标签)。然后,我们将这个词与我们从许多文档中收集并增加同义词后得到的关键词进行比较,以确认是否为关键词。如果不是关键词,我们将搜索它的所有同义词并将它们与关键词进行比较。第三,我们从动词的位置开始向后遍历句法树,寻找与该动词相关的否定词和情态动词(即,“aux”标签),以确定具体的关系。
根据上述所述,关系可以以完全不同的方式进行声明。首先,同一关系可以由多个关键词来声明。其次,同一关键词所描述的关系在不同的语境中可能有所不同。例如,关键词"use"分别在"must be used"、"be used"和"must not be used"中表示依赖关系、中立关系和冲突关系。
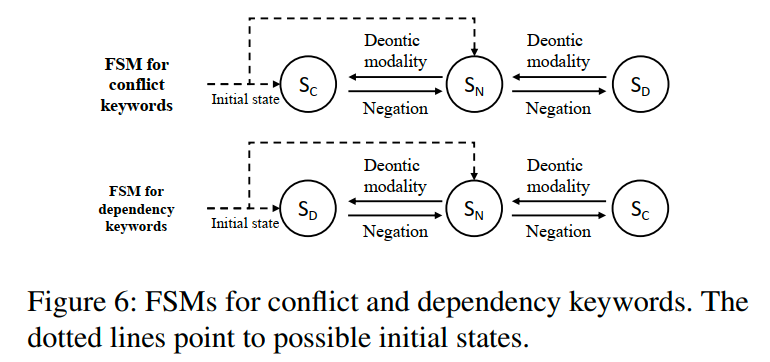
基于语言学的观点,冲突和依赖可以看作是一对极端对立的项目,而中立是这两种极性之间的中间状态(即既不是冲突也不是依赖)。这三个项目可以根据特定的句子成分(如关键词、德意义情态动词(例如"must"、"should"和"have to")和否定词)进行转换。
我们使用两个有限状态机(Finite State Machine,FSM)来描述状态转换过程,如图6所示。FSM的选择与基于语义的关键词分类有关,包括冲突和依赖关键词。每个FSM包含三个状态:SD(依赖关系)、SN(中立关系)和SC(冲突关系),以及两个可能的初始状态。FSM的初始状态是关键词的默认关系,即不带德意义情态动词和否定词的关系(附录C)。例如,由于"be used"表示中立关系,关键词"use"的默认关系是中立。确定了初始状态后,我们可以根据句子中的德意义情态动词和否定词推断出最终的状态,即所表示的关系。需要注意的是,根据语言学观点,德意义情态动词在否定词下具有作用范围,这意味着当两者同时存在时,只有否定词起作用。以句子"-A must not be used with -B and -C"为例。由于关键词"use"是一个依赖关键词,选择底部的FSM,并将初始状态设为中立。由于句子中既有德意义情态动词又有否定词,只有否定词起作用。根据依赖关键词的FSM,状态将从中立转变为冲突。
提取隐含声明的关系。对于隐含的句子,它们被确定为冲突的声明,并且我们只需要将这些句子映射到相应的选项,这在图2中的步骤1中已经完成。例如,根据第3.3节中的方法,我们可以知道句子"Force output to be written with Big-Endian byte order"和"Force output to be written with Little-Endian byte order"是隐含的R-句子。根据选项和句子之间的对应关系,我们可以知道这两个句子分别属于-B选项和-L选项。最后,我们提取了-B和-L选项之间的冲突关系。
最终,通过我们的关系提取方法,我们成功地从20个热门程序文档中提取出了282个关系,精确度和召回率分别为96.10%和88.85%。
3.5 Combination and Prioritization
根据选项之间提取的关系,我们可以过滤掉所有无效的选项组合。具体来说,我们将长度为n(0≤n≤k,其中k是选项的数量)的所有选项组合起来,并根据提取的关系对生成的组合进行有效性检查。只有满足所有依赖关系且没有冲突的组合被视为有效。对于可以具有值的选项,我们从文档中手动收集了每个选项的合理值,并在每个组合中随机选择一个值。
尽管过滤掉了无效的组合,这些组合占据了总组合数的大部分(例如,在opensslrsa中占99.84%),但剩下的有效组合的数量仍然可能很大(例如,成百万计),而测试所有这些组合是不切实际的,需要大量的计算资源。在本文中,我们利用N-wise测试[57]进一步剪枝需要测试的组合。这种测试是组合交互测试的一种有效方法,通过关注N个因素相互作用引起的缺陷,大大减少了需要测试的组合数。根据研究,几乎所有缺陷都是由不超过六个因素的交互作用引起的[27]。因此,我们使用6-wise(N = 6)测试来剪枝有效的选项组合。
N-wise测试是一种软件测试方法,用于确定在给定的输入组合或场景中测试软件系统的各种可能情况。这种测试方法旨在通过选择恰当的测试用例,以覆盖系统中所有可能的组合和交互,从而最小化测试的复杂性和成本。
在N-wise测试中,N表示被测试系统的参数数量。该方法通过选择一组测试用例,确保每个参数的所有可能取值都得到覆盖,并且所有参数之间的交互也得到考虑。通过使用N-wise测试,可以减少测试用例的数量,同时保持对系统的充分覆盖,从而提高测试效率和准确性。
例如,如果一个系统有10个参数,每个参数有3个可能的取值,那么在进行2-wise(也称为pairwise)测试时,可以通过选择仅包含所有参数两两组合的测试用例集合来进行测试。这样就可以仅使用30个测试用例,而不是1000个来测试系统的各种组合可能性。
N-wise测试是一种常用的测试方法,在软件开发中广泛应用,特别是对于具有大量参数和复杂交互的系统。它可以帮助识别潜在的问题和错误,并提高软件系统的质量和稳定性。
在剪枝组合之后,我们根据它们在相同种子文件的干扰运行中的覆盖范围对每个组合进行优先级排序。具体来说,覆盖范围更大的组合将具有更高的优先级。我们使用这种优先级排序技术主要考虑了两个方面。首先,在干扰过程中使用覆盖范围更大的组合进行模糊测试更有可能发现新的路径。其次,对于一些在先前步骤中未被识别的无效组合,我们的优先级排序技术可以降低它们的优先级,减少它们被测试的机会。
进行组合模糊测试。最后,我们使用所有经过优先级排序和剪枝处理的选项组合对每个程序进行模糊测试。具体而言,我们对目标程序进行插桩,使其能够从文件中读取选项,并允许模糊测试工具在运行过程中修改文件以切换使用的组合。在模糊测试开始时,我们使用所有给定的组合对种子文件进行变异,并在生成新的测试用例时记录相应的组合。然后,我们使用相应的组合对队列中的每个测试用例进行变异。
4 Implementation
本节介绍了我们在研究中使用的CarpetFuzz原型的实现,包括数据集收集、模型训练、自然语言处理分析、优先级排序和模糊测试等内容。
数据集收集。我们通过从Debian Manpages项目[12]中爬取所有命令行程序(37,672个)的manpages来收集训练数据集,这是Debian中包含的所有manpages的完整存储库。 值得注意的是,文档有三种形式,即manpages、在线文档和帮助命令。考虑到在线文档通常是由manpages生成的,并且帮助命令的输出通常很简短,由于空间限制,不具备我们所需的信息,因此我们选择解析manpages。 在爬取这些manpages后,我们基于GNU roff语言(即Groff)[56]提取了选项部分的内容,并将每个选项映射到其描述。具体而言,我们删除了Groff中定义的所有格式标签,并通过段落分隔符(“.TP”和“.IP”标签)区分不同的选项。我们将多个选项之间的内容视为它们的描述。然后,我们使用spaCy [47]进行句子分割。最后,我们收集了与选项相关的302,875个句子(去重后为228,827个句子)。
spaCy是一个流行的自然语言处理(NLP)库,用于处理和分析文本数据。它提供了一套功能强大的工具和API,可以进行分词、词性标注、命名实体识别、依存句法分析、句法解析等多项任务。 [基于Python]
模型训练。我们使用了Gensim库[42]中的Word2Vec模型将单词映射为向量,并使用以下参数进行训练:size = 300,window = 5,以及其他默认设置。由于选项的描述中可能包含选项本身,我们在预处理过程中将句子中的选项名称转换为"option_itself"和"option_other"。我们使用XGBoost对与选项相关的句子进行分类,实验证明XGBoost[7]相比其他机器学习模型(如SVM [10]和RF [21])具有更好的性能。我们使用默认超参数在初始数据集(297个正样本和139个负样本句子)上训练初始模型。在主动学习过程的每次迭代中,我们选择20个(K=20)信息熵最高的句子进行手动标记,并使用网格搜索[28]得到的最佳超参数重新训练模型。我们在连续70次迭代后停止训练(即T = 70)。最终模型的超参数为:max_depth = 6,n_estimators = 200,colsample_bytree = 0.8,subsample = 0.8,learning_rate = 0.1,以及其他默认设置。
NLP分析。我们使用NLTK [39]输出单词的所有词性,并使用LemmInflect [2]将动词转换为加主语后的第三人称单数形式。我们利用spaCy进行句子分割,提取第一句话,并使用依存解析为每个单词标注依存关系标签。对于短语结构解析,我们使用AllenNLP库[24]构建解析树,并基于“SBAR”标签提取从句。在分析中,我们发现不同的数字会导致不同的依存解析结果,这是自然语言处理模型的一个缺陷。为了修正这个问题,我们移除了所有非选项数字。
优先级和模糊测试。我们使用PICT工具[34]实施了6种测试,并根据提取的关系自动生成模型文件,以指定对组合的限制。我们使用afl-showmap [62]计算干扰运行时的边覆盖信息作为排序准则,并使用LLVM pass [53]来为目标程序注入工具。
5 Evaluation
本节描述了我们对CarpetFuzz的评估,包括其端到端操作和各个组件的有效性。
真实世界数据集。在这个评估中,我们评估了CarpetFuzz在最新版本的20个热门真实世界程序上的有效性(附录D)。这些程序处理11种不同类型的输入文件,包括图像(TIFF和JPG)、证书(PEM)、文本(MD和JSON)、流量数据包(PCAP)、可执行文件(ELF)、归档文件(LRZ)、音频(OGG和SPX)和文档(PDF)。我们选择这些程序是因为它们是广泛使用的具有十多个选项并持续维护的程序。我们从编译目录(即"share/man/man1/")中收集了它们的最新man页面,并手动提取了所有的R-sentences和关系进行评估。每个程序的选项数量和关系数量如附录D所示。
实验设置。我们使用CarpetFuzz来增强AFL [63],并将其与原始的AFL进行对比,以展示CarpetFuzz如何帮助改进AFL。为了突出CarpetFuzz的效果,我们还选择了AFLfast [4]、MOPT-AFL [32]和AFLplusplus [14]的最新版本进行对比,这些是基于AFL的最受欢迎的改进模糊测试工具之一。每个模糊器都以相同的单个种子文件开始,这些种子文件来自AFL目录、测试目录(用于PEM和MD格式)或在线文集[35](用于OGG和SPX格式)。我们连续在测试程序上进行48个 CPU 小时的模糊测试,并重复实验五次,以避免[26]中提到的模糊器固有不确定性的影响。我们的实验是在一台配置为Intel Xeon Platinum 8268处理器、24个CPU核心和188GB RAM的机器上进行的,该机器运行Ubuntu 20.04.5 LTS操作系统。
Research Questions. 在接下来的章节中,我们旨在回答以下研究问题
- RQ1. CarpetFuzz的性能如何?
- RQ2. 关系识别的准确性如何?
- RQ3. 关系提取的准确性如何?
- RQ4. CarpetFuzz的优先级技术的有效性如何?
- RQ5. 与最先进的技术相比,CarpetFuzz的模糊测试性能如何?
- RQ6. CarpetFuzz能否发现真实世界的漏洞?
5.1 Performance of CarpetFuzz (RQ1)
在这个实验中,我们旨在评估CarpetFuzz的性能。为了突出CarpetFuzz对AFL性能的改进,我们将评估指标定义为仅由CarpetFuzz覆盖的边的数量。
根据20个程序的man页,CarpetFuzz提取了282个关系,并平均过滤掉67.91%的选项组合(附录E)。借助这些关系,CarpetFuzz将这20个程序中需要测试的选项组合减少了25.00%至99.85%。可以看出,在存在复杂选项之间关系的程序(如openssl-rsa和eu-elfclassify)中,CarpetFuzz能够大大减少需要测试的组合数量。我们手动标记了这些程序中的关系,以评估过滤无效选项组合的过程。精确度和召回率分别在68.46%至100%和70.00%至100%之间,平均值为98.01%和94.19%,表明CarpetFuzz能够准确地识别和过滤掉无效选项组合。需要注意的是,在pdftotext和tiffcp(第5.3节)中只发生了少量误判,但由于总关系数量较少,这些误判占所有提取的关系比例较高,导致了较低的精确度/召回率(68.48%/70.00%)。
在过滤掉无效选项组合后,我们使用第3.5节提到的6-wise测试进一步修剪剩余的组合。为了评估修剪是否会导致覆盖率的损失,我们随机抽样每个程序的10万个有效组合进行比较(附录F)。结果显示,与随机抽样相比,我们的修剪技术能够减少更多的组合(98.91%),同时仅略微损失覆盖边的数量(2.54%)。
然后,我们使用AFL、AFLfast、MOPT-AFL和AFL++对每个程序进行模糊测试,其中不带选项(或最少的选项使其能够运行),并按优先顺序使用CarpetFuzz进行修剪后的选项组合模糊测试。每个模糊测试工具的代码覆盖增长曲线在48小时内趋于收敛,这表明这些模糊测试工具的代码覆盖最终稳定下来,并且使用48小时的覆盖率基本上代表了这些模糊测试工具每次运行的覆盖能力。
我们使用AFL能够达到的边缘作为基准来评估CarpetFuzz的性能。由于固有的不确定性,同一模糊测试工具的每次运行的覆盖率可能会有很大差异,因此单个覆盖率无法代表模糊测试工具的覆盖能力。相反,我们将五次运行的覆盖率取并集,以表示模糊测试工具能够到达的边缘。我们定义了测试模糊测试工具的唯一边缘数(对于基准不可达的边缘)为n,唯一边缘比率为r,公式如下:
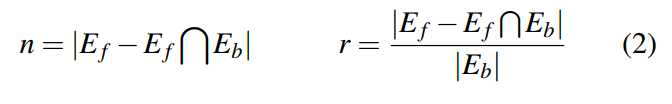
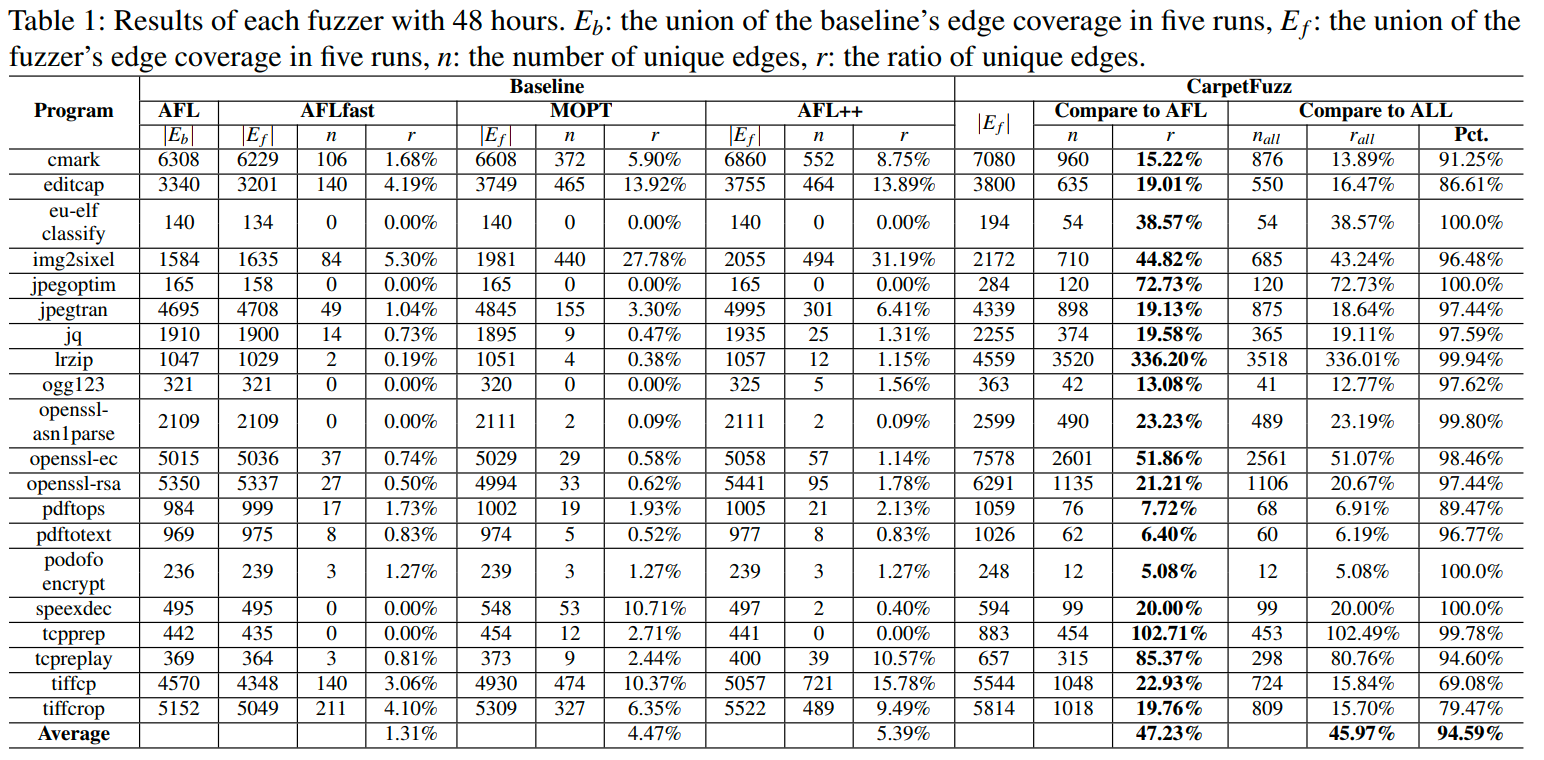
其中表示模糊测试工具在五次运行中的边缘覆盖的并集,表示基准在五次运行中的边缘覆盖的并集。然后,我们统计了每个模糊测试工具的唯一边缘数和比率,如表1的前14列所示。以AFL为基准,AFLfast找到的唯一边缘最少,在这20个程序上的唯一边缘比率平均为1.31%,这可能是因为AFLfast主要改进了AFL的种子调度策略以加速覆盖曲线的收敛。MOPT和AFL++比AFLfast找到更多唯一边缘,这两个模糊测试工具的唯一边缘比率分别为4.47%和5.39%。我们认为MOPT和AFL++的性能比AFLfast要好得多,可能是因为它们改进了AFL的变异策略。然而,即使没有优化AFL的任何策略,CarpetFuzz找到的唯一边缘最多,平均唯一边缘比率为47.23%。在所有这20个程序上,CarpetFuzz的比率都高于其他模糊测试工具,并且最高可达336.20%(对于lrzip),至少是其他模糊测试工具比率的293.33倍(AFL++)。结果表明,对于一些程序,如eu-elfclassify和jpegotim,改进模糊测试策略可能只能发现少量的唯一边缘,但通过指定某些有效的选项组合可以缓解这个问题。我们还将前四个模糊测试工具的边缘取并集,以调查CarpetFuzz找不到其他模糊测试工具可以发现的边缘数量,如表1的最后三列所示。结果显示,CarpetFuzz的唯一边缘中有平均94.59%其他模糊测试工具没有发现,CarpetFuzz可以帮助AFL平均找到多出45.97%的无法被其他模糊测试工具发现的边缘。
5.2 Accuracy of Relationship Identification (RQ2)
在明确声明关系的识别准确性方面。在主动学习过程中,我们进行了70次迭代,并收集了1817个手动标记的数据作为训练集。我们使用最终模型对数据集中的所有句子进行了预测(除了训练和验证集),其中7483个句子被预测为正例,221344个句子被预测为负例。我们从每个类别中随机抽取了500个句子进行手动标记以进行评估。模型在评估数据集上的准确率为92.90%,表明具有较高的准确性。误报率为11.49%,召回率为98.42%,说明我们的方法更少将R-sentences错误地识别为非R-sentences,因此可能避免错过一些关系。
然后,我们对20个程序的手册句子评估了我们的模型。根据手动标注结果,这些文件中的2952个句子中有75个明确的R-sentences。我们的模型将76个句子预测为正例,其中包括9个误报和8个漏报。准确率为98.80%,而误报率和召回率分别为0.67%和89.33%。尽管这个数据集的准确率更高,但其F1分数(0.89)比之前的评估数据集(0.92)要低。主要原因可能是该数据集不平衡。需要注意的是,这九个误报中有八个被判定为中立并在关系提取过程中被忽略(第3.4节中描述),这并不会影响到提取结果。
识别隐式声明的冲突准确性。从这些文件中,我们找到了232对唯一的隐式声明的冲突对。我们使用3.2节中的方法进行了识别,并找到了218对这样的冲突对,其中误报和漏报分别为9和23。准确率为95.87%,召回率为90.09%,说明我们的方法在识别隐式声明的冲突方面表现良好。经过分析,这九个误报都是由于缺乏相关的常识造成的。例如,在tiffcrop中,“-X”和“-Y”选项的主题句是“将相对于指定的参考原点设置区域的水平/垂直尺寸。”虽然两个选项都是“设置尺寸”,但我们的工具不知道水平和垂直尺寸是有区别的,需要人类常识。七个漏报也是由于缺乏相关的常识。在jpegoptim的“-s”选项的主题句中,“从输出文件中去除所有标记”,我们的工具不知道“所有标记”指的是各种标记而不是特定的标记。因此,它错过了“-s”选项和去除单个类型标记的选项之间的隐式声明的冲突。七个漏报来自于NLP解析器(如SpaCy)的不准确解析结果。例如,在两个具有相同结构的主题句中,“output monochrome sixel image”和“output 15bpp sixel image”,解析器将“monochrome”判断为名词,而将“15bpp”视为数字,导致这些句子被误认为是非平行的,因此被识别为非冲突。九个漏报是由于主题句中存在细微差异。例如,“-pvk-strong”和“-pvk-none”选项的主题句分别是“Enable Strong PVK encoding level”和“Don’t enforce PVK encoding。”由于动词(enable versus enforce)和对象(level versus encoding)都不同,我们的工具无法从这些句子中识别隐式声明的冲突。有趣的是,我们发现这样的遗漏冲突可以从它们的命名中识别出来。
5.3 Accuracy of Relationship Extraction (RQ3)
经过手动标注,我们从20个程序中找到了305种关系,其中包括284种冲突和22种依赖关系。我们的工具找到了282种关系,其中264种是冲突,18种是依赖关系。冲突的准确率和召回率分别为95.83%和89.40%,而依赖关系的准确率和召回率则分别为100%和81.82%。所有关系的准确率和召回率分别为96.10%和88.85%,说明我们的工具在提取关系方面表现良好。我们发现提取依赖关系可能更具挑战性,导致召回率较低,准确率较高。在四个依赖关系的误报中,两个是由于模型误报,另外两个是由于无法找到对应的选项。例如,在pdftotext的R-sentence中,我们的模型识别出“在所有其他模式下都会被忽略”,但我们的工具无法找到对应的选项。“实际上,即使是人类也很难找出与这些“模式”相对应的选项。例如,只有当我们将-layout选项的名称与-table选项的描述“表格模式类似于物理布局模式”结合起来时,我们才能发现-layout选项对应于物理布局模式。”在冲突关系的11个误报和30个漏报中,其中5个和32个分别是由于无法识别R-sentence和隐含声明的冲突(在5.2节中提到);两个是由于无法找到对应的选项;另外两个是由于缺乏人类常识而导致的错误提取。-RSAPublicKey_in和-RSAPublicKey_out选项被放在一起,并共享描述“与-pubin和-pubout相似,只是使用RSAPublicKey格式。”由于描述的主语不是复数形式,我们的工具错误地将这两个选项视为同一个选项,导致出现了一个误报(即-RSAPublicKey_in与-pubout之间的冲突)和一个漏报(即-RSAPublicKey_out与-pubout之间的冲突)。
5.4 Effectiveness of Prioritization Technique (RQ4)
为评估我们在第3.5节中提到的优先级技术的有效性,我们从我们的真实数据集中随机选择了十个程序,并为每个程序提供了五个打乱顺序的修剪后的有效组合列表(CarpetFuzzRand),以与优先级组合进行比较。每个组合列表进行了48小时的模糊测试。然后,我们将唯一路径的平均数量作为评估指标定义为:
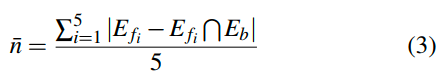
在公式中,表示第5.1节中基准测试(AFL、AFLfast、MOPT和AFL++)在五次运行中的边覆盖的并集,代表它们的覆盖能力。表示CarpetFuzz和CarpetFuzzRand在第i次运行中的边覆盖。结果如表2所示。通过我们的优先级技术,CarpetFuzz在每个程序上找到了其他模糊器无法发现的更多边(平均多出7%),证明了这项技术在找到更多独特边的能力方面是有效的。在三个程序中,改进更为明显(超过10%)。特别是在openssl-ec中,CarpetFuzz发现的独特边比CarpetFuzzRAND多出20%。在七个程序中,找到独特边的能力略有改善(在5%之内)
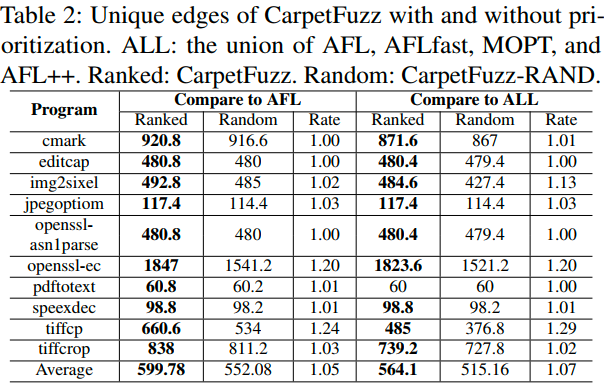
有趣的发现。在分析具有最低优先级的这些组合时,我们发现一些冲突只在运行时声明。例如,img2sixel中有四个冲突(-P与-8、-p与-e、-p与-I、-p与-b),在任何在线文档、man页或帮助命令中都没有声明。只有当我们使用这些组合之一运行程序时,才能得到一些提示,比如“选项-p,--colors与-I,--high-color冲突”。我们还发现,在tiffcrop中有两个依赖关系在运行时被声明为冲突(-K与-S,-J与-S)。我们在源代码中找到了作者留下的注释:“也许某天会实现,但现在还不行”,这意味着文档中存在这些依赖关系,但尚未实现。虽然这些无效组合在之前的步骤中被忽略了,但我们的优先级技术仍然通过对干扰运行的覆盖率进行排序,并将它们赋予最低优先级而找到了它们。
本文作者:Du4t
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!