请注意,本文编写于 932 天前,最后修改于 932 天前,其中某些信息可能已经过时。
目录
🤔
手写数字判断
数据集: mnist
简单全连接神经网络
最基础的如果不使用卷积神经网络 而使用全连接神经网络的话 可以简单设计一个架构
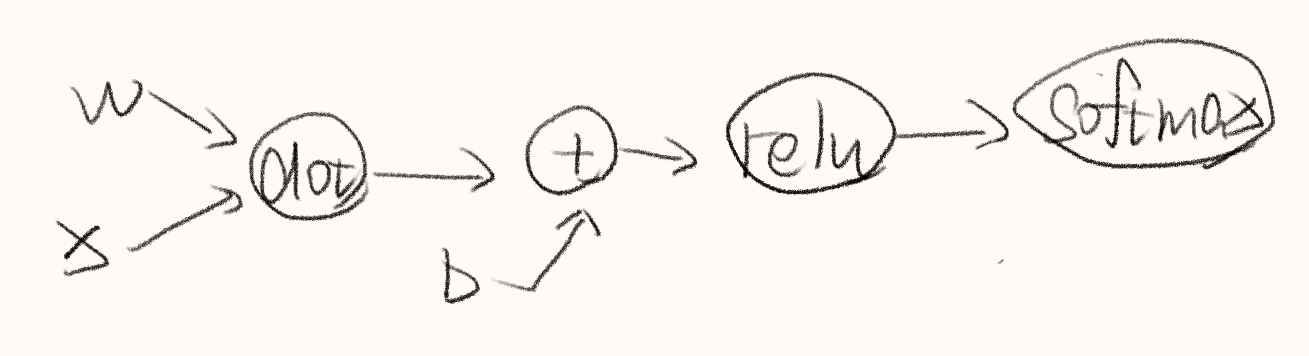
pythondef simple_network2():
EPOCHS = 50
BATCH_SIZE = 128
VERBOSE = 1
NB_CLASSES = 10
N_HIDDEN = 128
VALIDATION_SPLIT = 0.2
mnist = keras.datasets.mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data() # 此时X_train的shape为(60000, 28, 28) 也就是每张图像为一个二维数组 表示对应位置的像素值
RESHAPED = 784
X_train = X_train.reshape(60000, RESHAPED) # 将训练集重新reshape成为一个一维数组 便于输入到神经网络中
X_test = X_test.reshape(10000, RESHAPED) # 将测试集进行相同操作
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train, X_test = X_train / 255.0, X_test / 255.0 # 归一化处理 将一个像素值的范围缩小到0~1之间 这样做的好处是提高模型的收敛速度和稳定性
Y_train = tf.keras.utils.to_categorical(Y_train, NB_CLASSES) # 将其转化为one_hot类型
Y_test = tf.keras.utils.to_categorical(Y_test, NB_CLASSES)
model = tf.keras.models.Sequential() # 层与层之间顺序执行
model.add(keras.layers.Dense(N_HIDDEN, input_shape=(RESHAPED,), name='dense_layer', activation='relu'))
'''
N_HIDDEN: 神经元数量
input_shape: 指定了输入数据的形状 这里我们输入的肯定是上面已经reshape成一维数组的训练集数据
name: 指定了该层的名称
activation: 激活函数
'''
model.add(keras.layers.Dense(N_HIDDEN, name='dense_layer2', activation='relu')) # 后续的层会自动推断输入形状
model.add(keras.layers.Dense(NB_CLASSES, name='dense_layer3', activation='softmax')) # 输出层 神经元个数为数据种类
model.summary()
model.compile(optimizer='SGD', loss='categorical_crossentropy', metrics=['accuracy'])
'''
compile() 设定训练参数 将所有层编译到一起
optimizer: 优化器类型 这里使用的是随机梯度下降(SGD)
loss: 损失函数 这里使用的是分类交叉熵(categorical_crossentropy)
metrics: 衡量指标 这里使用的是准确率(accuracy)
'''
history = model.fit(X_train, Y_train, batch_size=BATCH_SIZE, epochs=EPOCHS, verbose=VERBOSE, validation_split=VALIDATION_SPLIT)
'''
fit() 开始训练
X_train: 输入的训练集数据
Y_train: 对应训练集的标签数据
batch_size: 单次输入到神经网络的数据个数
epochs: 数据集重复次数
verbose: 日志详细程度 0-2
validation_split: 从训练集中划分一部分为测试集
'''
model.save('mnist_model.h5') # 保存模型
train_acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
train_loss = history.history['loss']
val_loss = history.history['val_loss']
# 绘制准确率曲线
plt.plot(range(1, len(train_acc) + 1), train_acc, label='Training Accuracy')
plt.plot(range(1, len(val_acc) + 1), val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# 绘制损失曲线
plt.plot(range(1, len(train_loss) + 1), train_loss, label='Training Loss')
plt.plot(range(1, len(val_loss) + 1), val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
test_loss, test_acc = model.evaluate(X_test, Y_test)
'''
evaluate() 使用测试集对训练出来的模型进行评估
X_test: 测试集数据
Y_test: 测试集标签
'''
print("Accuracy: ", test_acc)
可以看到随着训练次数的增加 准确率在不断上升 虽然最后通过总览来看 发生了过拟合 但是影响不大 后面我们再改善这个问题
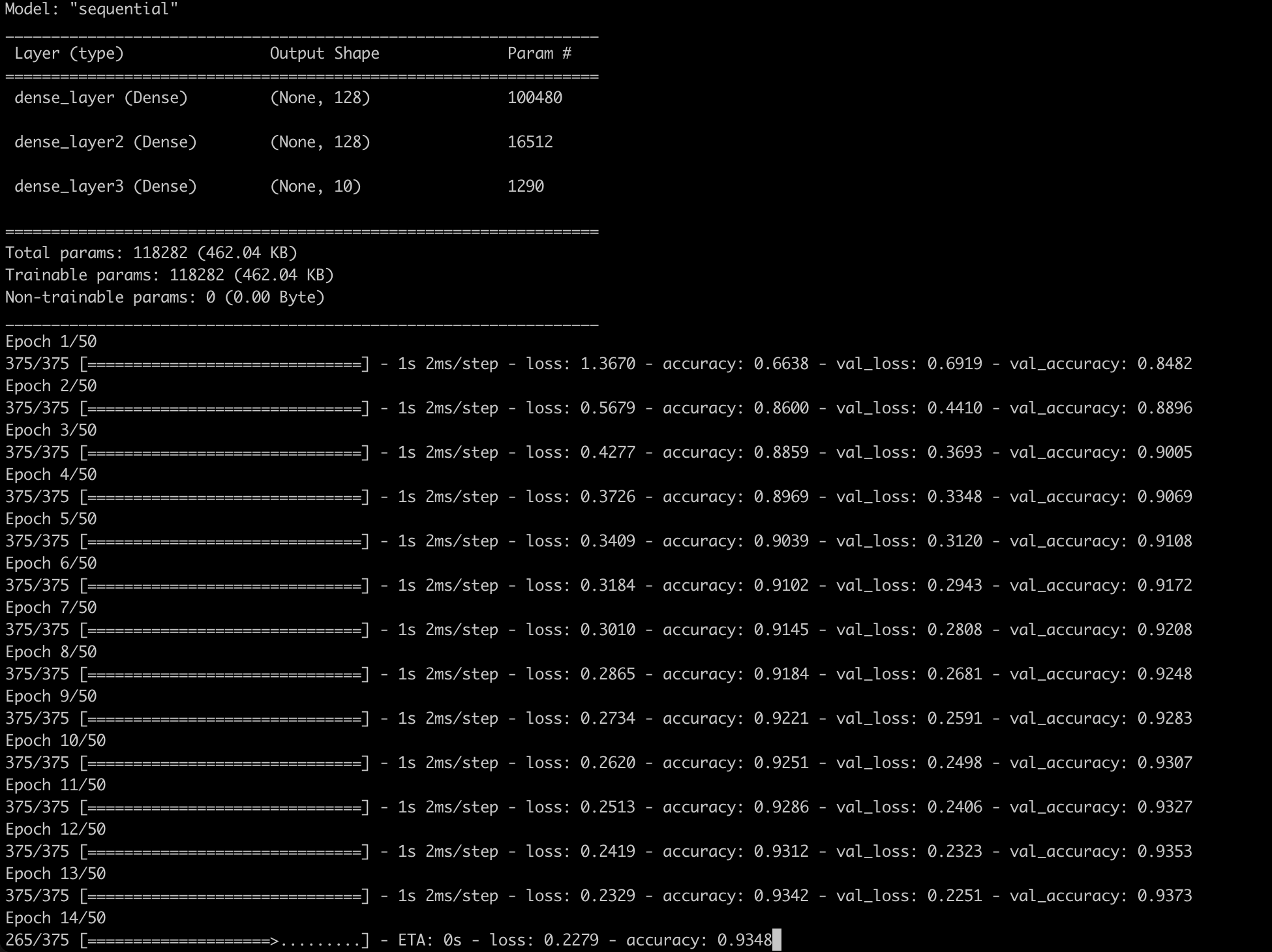
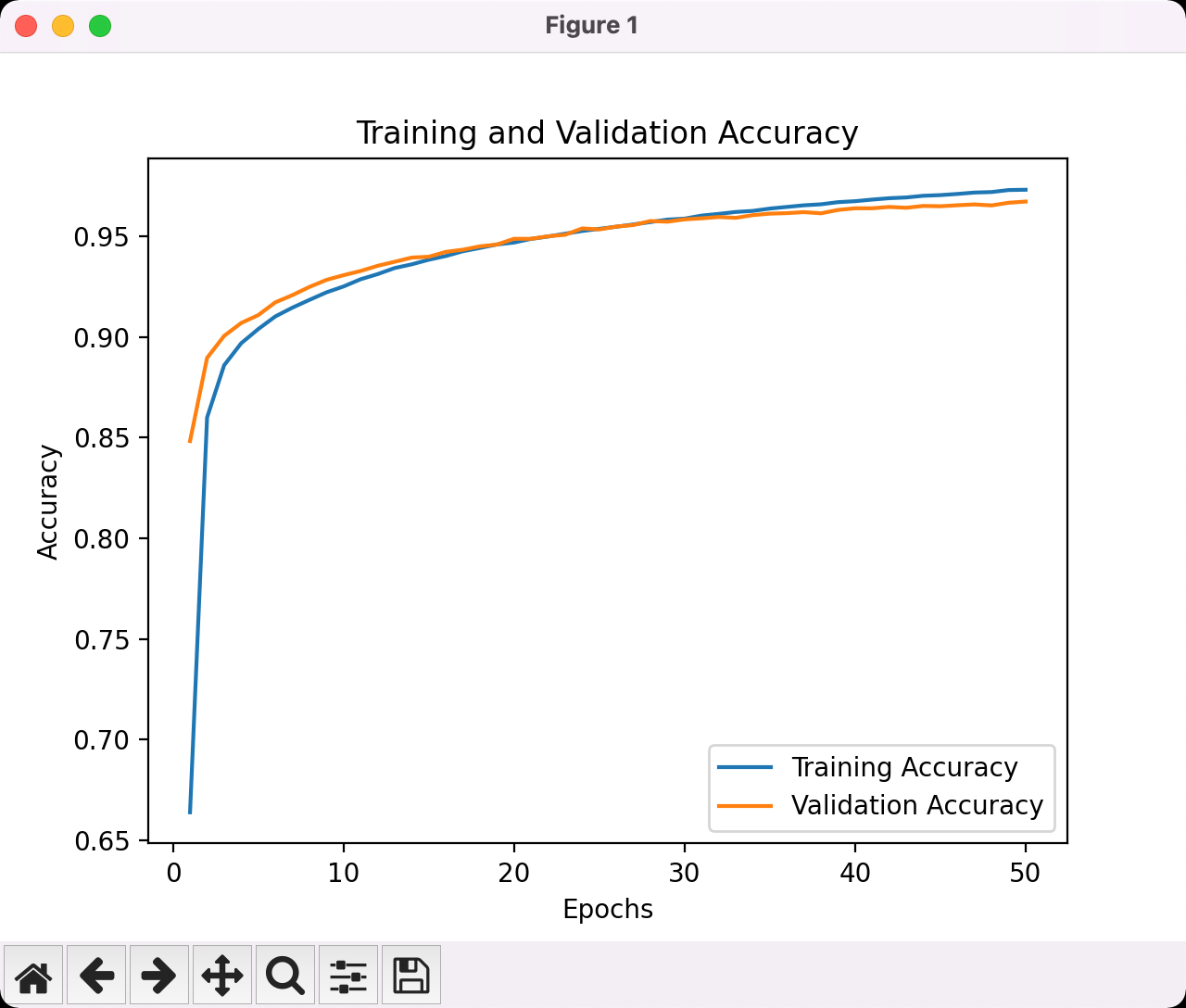
此时在测试集上的准确率为96%左右

这里就可以引入Dropout机制 在训练时随机使神经元失效 这样可以让其他神经元认为"除自己之外的神经元状况都不可靠" 即尽最大能力提高鲁棒性 代码层面改变很简单 在层与层之间新加Dropout层即可
pythondef simple_network2():
EPOCHS = 50
BATCH_SIZE = 128
VERBOSE = 1
NB_CLASSES = 10
N_HIDDEN = 128
VALIDATION_SPLIT = 0.2
DROPOUT = 0.3
mnist = keras.datasets.mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data() # 此时X_train的shape为(60000, 28, 28) 也就是每张图像为一个二维数组 表示对应位置的像素值
RESHAPED = 784
X_train = X_train.reshape(60000, RESHAPED) # 将训练集重新reshape成为一个一维数组 便于输入到神经网络中
X_test = X_test.reshape(10000, RESHAPED) # 将测试集进行相同操作
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train, X_test = X_train / 255.0, X_test / 255.0 # 归一化处理 将一个像素值的范围缩小到0~1之间 这样做的好处是提高模型的收敛速度和稳定性
Y_train = tf.keras.utils.to_categorical(Y_train, NB_CLASSES) # 将其转化为one_hot类型
Y_test = tf.keras.utils.to_categorical(Y_test, NB_CLASSES)
model = tf.keras.models.Sequential() # 层与层之间顺序执行
model.add(keras.layers.Dense(N_HIDDEN, input_shape=(RESHAPED,), name='dense_layer', activation='relu'))
'''
N_HIDDEN: 神经元数量
input_shape: 指定了输入数据的形状 这里我们输入的肯定是上面已经reshape成一维数组的训练集数据
name: 指定了该层的名称
activation: 激活函数
'''
model.add(keras.layers.Dropout(DROPOUT))
model.add(keras.layers.Dense(N_HIDDEN, name='dense_layer2', activation='relu')) # 后续的层会自动推断输入形状
model.add(keras.layers.Dropout(DROPOUT)) # dropout层 防止过拟合
model.add(keras.layers.Dense(NB_CLASSES, name='dense_layer3', activation='softmax')) # 输出层 神经元个数为数据种类
model.summary()
model.compile(optimizer='SGD', loss='categorical_crossentropy', metrics=['accuracy'])
'''
compile() 设定训练参数 将所有层编译到一起
optimizer: 优化器类型 这里使用的是随机梯度下降(SGD)
loss: 损失函数 这里使用的是分类交叉熵(categorical_crossentropy)
metrics: 衡量指标 这里使用的是准确率(accuracy)
'''
history = model.fit(X_train, Y_train, batch_size=BATCH_SIZE, epochs=EPOCHS, verbose=VERBOSE, validation_split=VALIDATION_SPLIT)
'''
fit() 开始训练
X_train: 输入的训练集数据
Y_train: 对应训练集的标签数据
batch_size: 单次输入到神经网络的数据个数
epochs: 数据集重复次数
verbose: 日志详细程度 0-2
validation_split: 从训练集中划分一部分为测试集
'''
model.save('mnist_model.h5') # 保存模型
train_acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
train_loss = history.history['loss']
val_loss = history.history['val_loss']
# 绘制准确率曲线
plt.plot(range(1, len(train_acc) + 1), train_acc, label='Training Accuracy')
plt.plot(range(1, len(val_acc) + 1), val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# 绘制损失曲线
plt.plot(range(1, len(train_loss) + 1), train_loss, label='Training Loss')
plt.plot(range(1, len(val_loss) + 1), val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
test_loss, test_acc = model.evaluate(X_test, Y_test)
'''
evaluate() 使用测试集对训练出来的模型进行评估
X_test: 测试集数据
Y_test: 测试集标签
'''
print("Accuracy: ", test_acc)
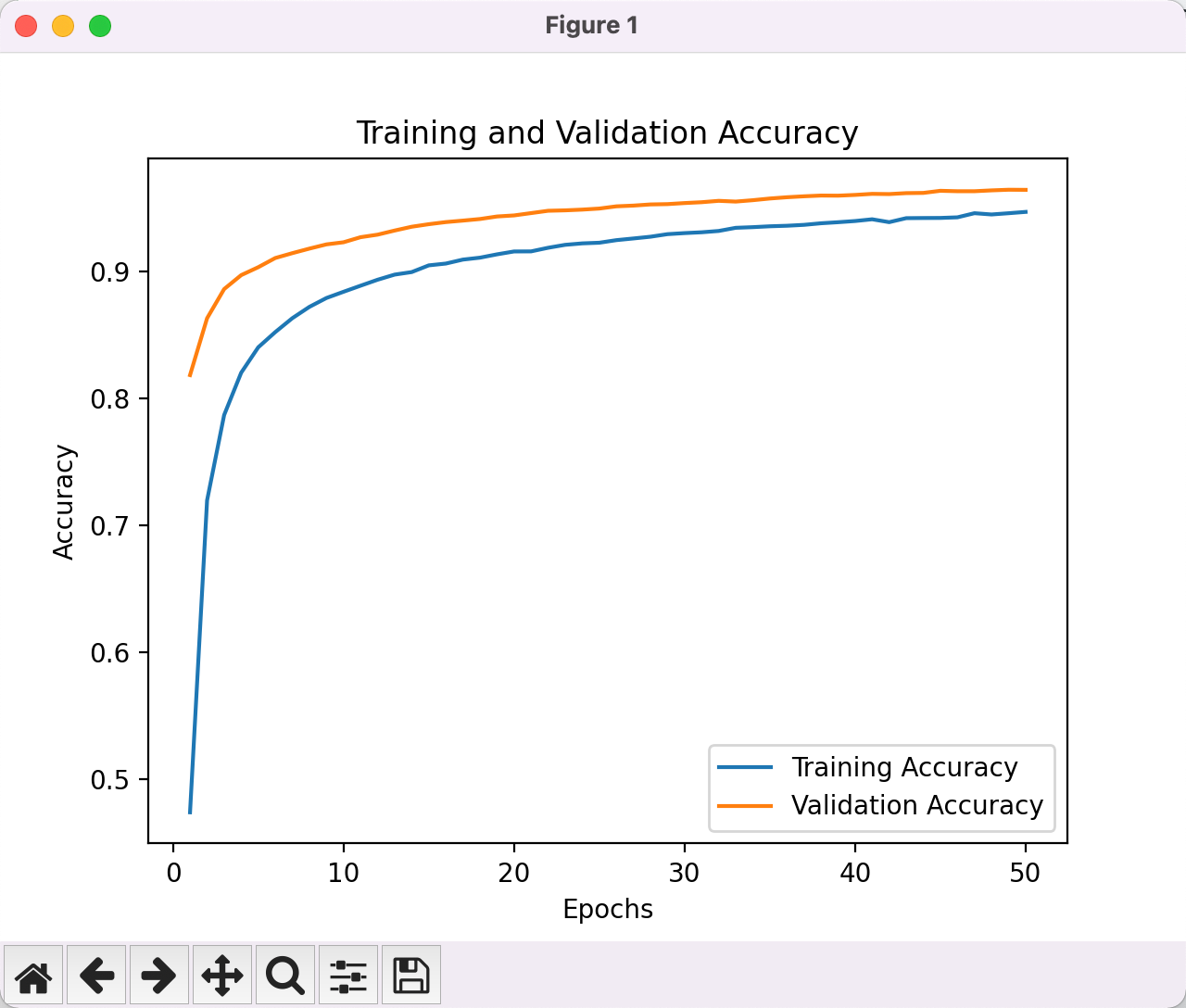
很显然我们成功抑制了过拟合现象 提高了模型的泛化能力 此时验证集准确率全程高于训练集是使用Dropout层正常现象 这里稍微修改一下源码 让其可以直接加载之前存在的模型进行训练 当然此时的模型准确率依然堪忧
pythondef simple_network2():
EPOCHS = 200
BATCH_SIZE = 128
VERBOSE = 1
NB_CLASSES = 10
N_HIDDEN = 128
VALIDATION_SPLIT = 0.2
DROPOUT = 0.3
mnist = keras.datasets.mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data() # 此时X_train的shape为(60000, 28, 28) 也就是每张图像为一个二维数组 表示对应位置的像素值
RESHAPED = 784
X_train = X_train.reshape(60000, RESHAPED) # 将训练集重新reshape成为一个一维数组 便于输入到神经网络中
X_test = X_test.reshape(10000, RESHAPED) # 将测试集进行相同操作
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train, X_test = X_train / 255.0, X_test / 255.0 # 归一化处理 将一个像素值的范围缩小到0~1之间 这样做的好处是提高模型的收敛速度和稳定性
Y_train = tf.keras.utils.to_categorical(Y_train, NB_CLASSES) # 将其转化为one_hot类型
Y_test = tf.keras.utils.to_categorical(Y_test, NB_CLASSES)
try:
model = tf.keras.models.load_model('mnist_model.h5')
except:
model = tf.keras.models.Sequential() # 层与层之间顺序执行
model.add(keras.layers.Dense(N_HIDDEN, input_shape=(RESHAPED,), name='dense_layer', activation='relu'))
'''
N_HIDDEN: 神经元数量
input_shape: 指定了输入数据的形状 这里我们输入的肯定是上面已经reshape成一维数组的训练集数据
name: 指定了该层的名称
activation: 激活函数
'''
model.add(keras.layers.Dropout(DROPOUT))
model.add(keras.layers.Dense(N_HIDDEN, name='dense_layer2', activation='relu')) # 后续的层会自动推断输入形状
model.add(keras.layers.Dropout(DROPOUT)) # dropout层 防止过拟合
model.add(keras.layers.Dense(NB_CLASSES, name='dense_layer3', activation='softmax')) # 输出层 神经元个数为数据种类
model.summary()
model.compile(optimizer='SGD', loss='categorical_crossentropy', metrics=['accuracy'])
'''
compile() 设定训练参数 将所有层编译到一起
optimizer: 优化器类型 这里使用的是随机梯度下降(SGD)
loss: 损失函数 这里使用的是分类交叉熵(categorical_crossentropy)
metrics: 衡量指标 这里使用的是准确率(accuracy)
'''
history = model.fit(X_train, Y_train, batch_size=BATCH_SIZE, epochs=EPOCHS, verbose=VERBOSE, validation_split=VALIDATION_SPLIT)
'''
fit() 开始训练
X_train: 输入的训练集数据
Y_train: 对应训练集的标签数据
batch_size: 单次输入到神经网络的数据个数
epochs: 数据集重复次数
verbose: 日志详细程度 0-2
validation_split: 从训练集中划分一部分为测试集
'''
model.save('mnist_model.h5') # 保存模型
train_acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
train_loss = history.history['loss']
val_loss = history.history['val_loss']
# 绘制准确率曲线
plt.plot(range(1, len(train_acc) + 1), train_acc, label='Training Accuracy')
plt.plot(range(1, len(val_acc) + 1), val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# 绘制损失曲线
plt.plot(range(1, len(train_loss) + 1), train_loss, label='Training Loss')
plt.plot(range(1, len(val_loss) + 1), val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
test_loss, test_acc = model.evaluate(X_test, Y_test)
'''
evaluate() 使用测试集对训练出来的模型进行评估
X_test: 测试集数据
Y_test: 测试集标签
'''
print("Accuracy: ", test_acc)

卷积神经网络
可以简单设计一个架构 即 卷积层 -> 池化层 -> 卷积层 -> 池化层 -> Flatten层 -> 全连接层
卷积层: 卷积网络内最重要的层 利用卷积核对图像特征进行识别 用于学习特征
池化层: 降低特征图的空间分辨率 减少计算量
Flatten层: 在卷积神经网络内 图像是二维数组的形式进行传递学习 在传入全连接层之前需要将其平展为一维数组
pythondef con_network():
EPOCHS = 200
BATCH_SIZE = 128
VERBOSE = 1
NB_CLASSES = 10
VALIDATION_SPLIT = 0.2
DROPOUT = 0.3
mnist = keras.datasets.mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data() # 此时X_train的shape为(60000, 28, 28) 也就是每张图像为一个二维数组 表示对应位置的像素值
RESHAPED = 784
X_train, X_test = X_train / 255.0, X_test / 255.0 # 归一化处理 将一个像素值的范围缩小到0~1之间 这样做的好处是提高模型的收敛速度和稳定性
X_train = X_train[..., tf.newaxis]
X_test = X_test[..., tf.newaxis]
Y_train = tf.keras.utils.to_categorical(Y_train, NB_CLASSES) # 将其转化为one_hot类型
Y_test = tf.keras.utils.to_categorical(Y_test, NB_CLASSES)
try:
model = tf.keras.models.load_model('con_mnist_model.h5')
except:
model = tf.keras.models.Sequential() # 层与层之间顺序执行
model.add(keras.layers.Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(keras.layers.MaxPool2D(pool_size=(2, 2)))
model.add(keras.layers.Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(keras.layers.MaxPool2D(pool_size=(2, 2)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(64, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
model.compile(optimizer='SGD', loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, Y_train, batch_size=BATCH_SIZE, epochs=EPOCHS, verbose=VERBOSE, validation_split=VALIDATION_SPLIT)
model.save('con_mnist_model.h5') # 保存模型
train_acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
train_loss = history.history['loss']
val_loss = history.history['val_loss']
# 绘制准确率曲线
plt.plot(range(1, len(train_acc) + 1), train_acc, label='Training Accuracy')
plt.plot(range(1, len(val_acc) + 1), val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# 绘制损失曲线
plt.plot(range(1, len(train_loss) + 1), train_loss, label='Training Loss')
plt.plot(range(1, len(val_loss) + 1), val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
test_loss, test_acc = model.evaluate(X_test, Y_test)
'''
evaluate() 使用测试集对训练出来的模型进行评估
X_test: 测试集数据
Y_test: 测试集标签
'''
print("Accuracy: ", test_acc)
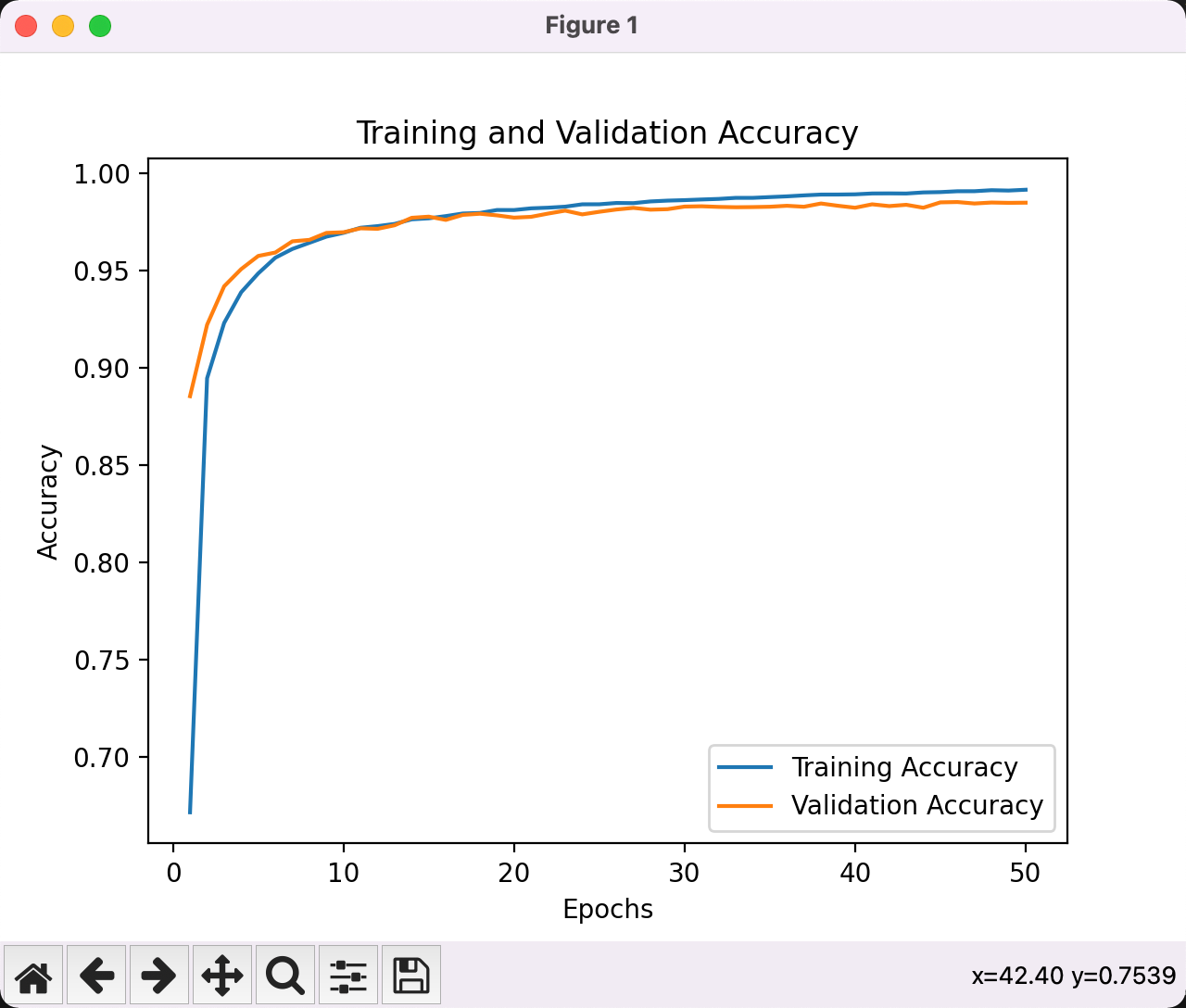
此时准确率提升到了98%

本文作者:Du4t
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录