目录
🤔
AIFORE: Smart Fuzzing Based on Automatic Input Format Reverse Engineering
- 不同输入字段的边界在哪里
- 这些字段属于哪些类型
- 如何利用输入格式知识指导Fuzz
作者
作者的观点
输入字段的结构和语义由处理他们的基本块来定义而不是输入规范。
现有的方法
现有输入字段边界识别的方法
现有的输入字段识别有统计分析和动态污点分析将同一个指令处理的字节分组到一个字段分组中。这样的做法存在的问题就是,一条指令可能在循环中处理多个输入字段,并且一个长字段大概率是被多个指令所处理,因为一条指令无法处理超过机器字长的数据。
现有的输入字段类型识别方法
现有的解决方案一般依赖于先验知识,例如strcpy的参数类型,但是这种方式需要大量的人工介入并且只能识别程序的变量类型而不是语义类型。
现有的利用格式知识指导Fuzz的方法
现有的方案都是针对结构良好的种子分配更多的能量以执行更多的突变,但是大部分方案都是没有字段间关系约束的,无法区分种子质量。
作者的方法
识别输入字段边界的方法
首先使用动态污点分析来确定每个基本块处理了哪些输入字节,因为单个不可分割的字段可能会被一个基本块中的多个指令处理但是大概率不会被多个基本块处理。根据污点分析结果使用最小聚类算法来确定不可分割字段的边界。
识别输入字段类型的方法
构建深度学习模型来预测基本块处理输入字段的类型和语义。
利用现有的格式知识指导Fuzz的方法
首先选择代码覆盖率显著不同的测试用例,其次选择在模糊测试中测试频率较低的种子。
设计架构
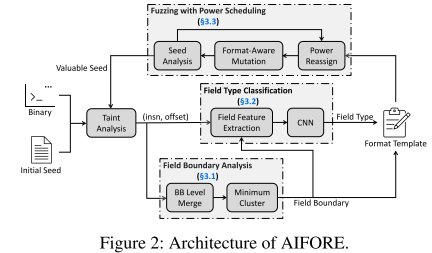
在模糊测试过程中,如果一个种子带来了大于3%的平均覆盖率提升,则将其标记为有价值的种子,而后使用AIFORE分析其格式,并且使用知识模型(提取的字段边界和字段类型知识)进行模糊测试。其中AIFORE使用污点分析构建输入字节和处理字节的基本块之间的映射关系,然后分别调用Field Boundary Analysis、Field Type Classification、Fuzzing with Power Scheduling三个模块。
其中Field Boundary Analysis模块主要是将输入分割成为字段;Field Type Classisfication模块主要是使用CNN模型预测字段类型信息;最终结合字段边界信息和字段类型信息组成格式模版(Format Template),其为一个pit文件,对于每个字段记录其边界和起始位置、大小、类型。
字段边界识别


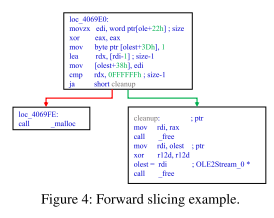
从BB中拆分字段的算法如算法1所示,首先从二进制程序中提取出所有的BB,然后针对二进制程序进行污点分析。利用污点分析出来的污染地址与BB做对应,将其存储在一个字典BB_to_taint中,而后针对字典中每一个受污染的BB,收集并合并在一个BB中处理的字节,而后根据BB和BB中受污染的字段来进行分割,针对于连续字节将作为同一个字段进行划分。例如图3中的第四行(18,19)字节将作为一个字段进行分割。

字段类型分类
这里的分类主要是想针对BB分类以提取出字段的语义类型,例如偏移量或者校验和等信息。而不是程序变量类型,例如int或者string。作者将所有字段分为了六种语义
- SIze:此类型的字段主要表示输入文件中一个或多个字段组成的数据块长度。例如ELF文件格式中偏移量为0x28的字段
e_ehsize表示ELF文件头的大小。 - Enumeration:此类字段只能采取一组有限的有效值,例如在ELF文件格式中的
e_type字段只能使用ELF格式中定义的七种有效值之一。 - Magic number:幻数。
- String:字符串文字,可以为ASCII、Unicode或者其他编码形式。
- Checksum:校验和,此类字段用于完整性验证,常见于媒体文件、压缩文件、字体格式中。
- Offset:偏移,此类字段用于指示输入中另一个数据块的位置,例如ELF文件格式中偏移为0x20处的
e_shoff表示节头的偏移量。
作者选用深度学习来使用机器学习以对BB进行字段类型分类,并且使用向前切片以合并对字段的重要操作。
Fuzz的能量调度
- 应该优先针对哪些种子执行格式提取?
- 如何平衡突变过程中针对不同格式变体的模糊测试?
首先针对初始种子进行分析以构建格式模型,而后在格式模型的指导下针对种子进行变异,如果新突变的种子有价值那么就重新分析其结构。如果Fuzzer长时间内无法获得新的覆盖范围的话,就将Fuzzer的能量分配给那些尚未完全变异的格式。

针对不同的字段变异方式也不同,针对每个字节Mutator会将其作为一个整体进行变异,例如Size字段会将其更改为一个合理值而不是位翻转。针对没有格式知识的字节,Mutator将使用AFL中的默认突变方式。
本文作者:Du4t
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!