目录
🤔
BENZENE: A Practical Root Cause Analysis System with an Under-Constrained State Mutation
作者
- Younggi Park - 高丽大学、国防部
- Hwiwon Lee - 高丽大学、国防部
- Jinho Jung - 国防部
- Hyungjoon Koo - 成均馆大学
- Huy Kang Kim - 高丽大学
现有的RCA方案
- 基于AURORA的统计学方案
- 缺点:用于崩溃探索的Fuzz技术不足以有效的收集RCA中适当的非崩溃行为;trace非常耗时
- ARCUS 预制规范模板的符号执行及崩溃重放
- 缺点:无法解决符号执行带来的路径爆炸和约束求解的问题;不能预定义所有漏洞类型
理论基础
崩溃必须满足每个崩溃触发条件。也就是说,崩溃的存在必须满足一组条件(即谓词)才能产生给定的崩溃,这意味着如果集合中的任何谓词已被否定,则不会发生崩溃,并且正常行为与崩溃行下的一个或多个谓词相矛盾。
我们假设目标程序(P)的行为对于给定的输入 I 具有明确的执行路径(即确定性)。我们将 P 中的漏洞表示为 V。然后可能有多个 I 因 V 而触发崩溃,每次崩溃的执行路径是唯一的。
提取RCA的思路
- 从所有谓词中提取出普通崩溃谓词
- 从普通崩溃谓词中提取出根本成因
作者的思路
本质上和AURORA类似,只是引入了一种运行时直接状态突变的欠约束状态突变方案来实现崩溃探索
- 为了解决目前针对崩溃样例和非崩溃样例获取的难题,作者引入了状态突变来有效地收集与给定崩溃相关的不同行为
- 为了解决从大量普通崩溃谓词中定位根本成因的难题,作者去除了比较过程,选择用行为相似度定位根本成因
状态突变:这是一种针对 RCA 量身定制的突变技术,可在运行时突变目标程序状态。该技术背后的关键思想是,导致崩溃的输入的一部分最终存储在处理器寄存器或进程存储器中。
Q1. 这样做状态空间不是更大了么,如何快速缩小状态空间?
我们采用三种突变策略来使我们的技术实用且稳健(§6.2)。令执行的指令为,其中表示某个程序中的所有指令。现在我们在执行指令的那一刻定义一个状态为,其中寄存器和存储器的当前状态分别表示为和。为了描述状态突变,我们定义两个属性:1个类型:,其中和表示要从中进行突变的源操作数或内存,以及 2 个值:然后,状态突变可以正式写为 其中状态转换是用值 到 类型。例如,图 4 中 i := lea esi, [rax+rax*4] 上的状态突变可以写为 注意,BENZENE 仅关注源操作数中的值突变,因为目标操作数中的值由其源自动确定。
突变总结:在高层次抽象来看上,BENZENE类似于 LibFuzzer和内存中模糊测试,我们通过分叉创建新进程来探索函数级别的程序行为。一旦提取了这些目标函数,我们就会以每个函数固定次数的迭代来重复状态突变。在每次迭代中,我们选择一个突变目标 Si(R,M)。当达到突变目标(Si)时,我们执行状态突变(Ti),相应地修改程序的当前状态。突变后,我们继续该过程直到终止并监视(非)崩溃。请注意,改变程序状态会使其容易发生意外崩溃;因此,我们设计了相关的突变策略。
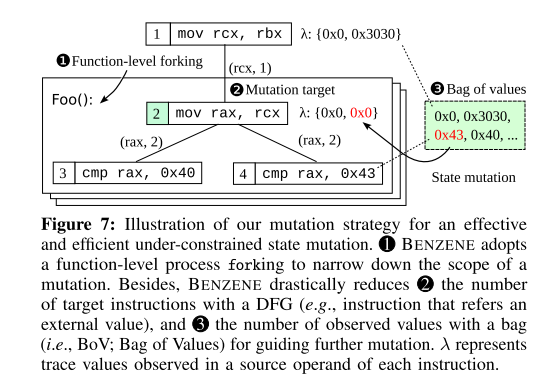
函数级Fork:由于程序中有大量指令,我们需要缩小状态突变的位置范围。为了解决这个问题,我们采用函数的粒度来进行突变过程( 例如图 7 中的 Foo())。具体来说,我们提取了与崩溃站点无效内存访问相关的函数列表。这可以在动态二进制分析期间使用函数信息和崩溃起源来执行(§5)。一旦确定了目标函数(例如 10 分钟),我们就为每个目标函数迭代一个状态突变 (F);即,1 在目标函数内选择状态突变 Ti : S → S′(即 i ∈ F),2 执行指令,3 监视突变结果(即崩溃或非崩溃)。对于每次迭代,该过程都会在目标函数的入口处分叉。
变异目标的选择:对于目标函数的每个分叉过程,我们必须选择一个状态 Si(R,M) 作为突变候选。尽管我们将突变范围限制在目标函数内,但仍然存在突变目标选择问题。对于目标函数的每个分叉过程,我们必须选择一个状态 Si(R,M) 作为突变候选。尽管我们将突变范围限制在目标函数内,但函数内仍然存在大量指令。为了解决这个问题,我们将指令缩小到引用外部值(来自函数边界外部)的指令选择池(即 i ∈ P,P ⊂ F)。背后的直觉是某个函数的行为可以由外部值(例如参数或全局变量)决定;因此,改变它们可以帮助产生理想的行为。我们利用 DFG (§5) 来识别在二进制级别使用此类外部值的指令。考虑图 7 中的 inst2,其中 inst2 的传入边为 (rcx, inst1)。影响值(即 rcx 中的值)源自外部函数(例如调用者)。由于inst2采用外部引用值,因此我们选择Sinst2(R,M)作为P中的突变目标。相比之下,数据流来自inst2的inst3可以从P中排除,因为rax依赖于rcx。值得注意的是,我们的方法与调用约定(即子例程如何从调用者那里获取参数的方案,例如 stdcall、cdecl 或 fastcall)无关,因为我们检查值是否来自寄存器或具有函数边界的记忆。
- Bag of Values: 由于其固有的不稳定性,欠约束的状态突变很容易导致不期望的无效崩溃。我们仔细的观察启发式地揭示了经常触发此类无效崩溃的两种主要情况:改变引用用户定义的数据类型(例如结构)的指针和改变具有不同范围的约束变量(例如枚举类型、数组索引)。为了处理这两种情况,我们维护一个Bag of Value (BoV) λ,以指导进一步的突变。该袋子在内部收集每个 Si(R,M) 的一组观察值(根据指令从源)。因此,可以从 Ti(t, v, v') 的 (即 v' ∈ λ) 中选择突变候选者 (v')。该策略背后的直觉是,共享相同数据流的值很可能具有相同的数据类型。这有助于观察可接受的行为,而不必担心二进制文件上的复杂类型推断。然而,它提供了在可接受的时间限制内覆盖大突变空间的机会。我们通过回溯 DFG 中的传入边(即,直到 DFG 中具有单个源边的点)(例如图 7 中的 3),从执行指令的存储值中培养每 S 的 BoV。 BoV 感兴趣的是一个特殊的值,它可以进入一个分支(例如,来自 cmp rax 的 0x40,0x40),使我们能够有效地收集非崩溃行为,例如模糊测试中的先前工作[76]、[111]、[ 124]。如果 BoV 超过预定义的大小(例如 1024),BENZENE 会进行随机抽样。使用 BoV,BENZENE 生成随机值 (RV),为每个突变周期从 BoV 或 RV 中概率选择一个值(例如 50%)。请注意,我们禁用了 ASLR,因为每个突变的内存布局在突变期间必须保持一致。
Q2. 直接更改状态空间按理来说是存在可能没有对应输入的,没有对应输入获取到的崩溃或者非崩溃谓词就是没有意义的?
人们可能会提出确保这种状态突变的行为有效性的问题,因为强制修改程序的中间状态通常会导致后续执行无效(例如,无法到达的状态)。然而,与模糊测试相比,我们的状态突变不需要推理输入的验证,而是利用突变本身来获得非崩溃行为。在这方面,我们的突变技术被称为欠约束状态突变,它是从欠约束符号执行中借用的。也就是说,即使存在不可行状态,非崩溃行为也是不满足崩溃条件的(副)产品,这可以帮助寻找根本原因(即崩溃条件)的候选谓词。举例来说,图 1 中第 4 行中 im1->sx 从 0xfff 到 0x0 的突变会导致非崩溃,因为它不包含崩溃条件下的谓词之一 [im1->sx > 0x0]。尽管此突变通过引导无法到达的分支(即,没有循环的转义)而导致不可行的执行,但其行为对于获取 RCA 的谓词很有用。我们在第 6.3 节中详细阐述了在约束不足的状态突变下崩溃行为的有效性。
虽然我们的欠约束状态突变技术主要集中于收集非崩溃行为,但有必要收集最小的崩溃行为集,因为我们利用了 AURORA 谓词合成的方法(等式 1)。然而,与可以确认其有效性的非崩溃行为相比,很难确定由状态突变引起的崩溃是否与原始崩溃相关联。例如,如果最初表示特定指针的目标被突变为无效整数(例如 0x1),则崩溃(与错误无关)将毫无意义。这种无效的崩溃通过在方程 1 中引入大量噪声而显着阻碍了准确崩溃条件的合成。基于先前的反向执行分类技术 [78]、[79]、[121],我们将某个崩溃分类为同一类别,如果遵循相同的数据流。然而,为每次崩溃执行构建 DFG 的成本很高,开销也很大。为了解决这个问题,我们设计了一种崩溃分类技术,可以将具有给定崩溃(即根本原因)的执行与具有无效状态突变的执行区分开来,同时产生较低的开销。该技术需要满足以下两个条件:1 由状态突变触发的崩溃站点(即地址)与初始崩溃相同,2 执行与崩溃起源相关的指令。如果状态突变的崩溃满足上述条件,我们记录此行为;否则,我们将丢弃它。显然,我们的方法可能会通过仅考虑 V 导致的所有可能崩溃的子集来合成过度近似的崩溃条件;然而,CR 仍将与子集一起保留。换句话说,CR 必须满足非崩溃不能满足的崩溃(一部分)。
Q3.


行为相似度:这种方法的关键见解是,在常见的崩溃情况下,非崩溃行为必须与一个或多个谓词相矛盾。我们的方法基于以下事实:给定崩溃和非崩溃之间的代码覆盖率越接近,就越有可能通过与崩溃中的谓词相矛盾来揭示 V 的根本原因。例如,表 1 列出了四种非崩溃行为(#1-4),每种行为至少与 C* 中的一个谓词(即灰色单元格)相矛盾。在这种情况下,与第一个非崩溃输入 (#1) 相矛盾的谓词 (p1) 最有可能成为 CVE2019-6977 的根本原因,因为 #1 是最接近初始崩溃(即 IC)的行为。利用主成分分析来计算非崩溃行为的相似度得分

整体框架结构
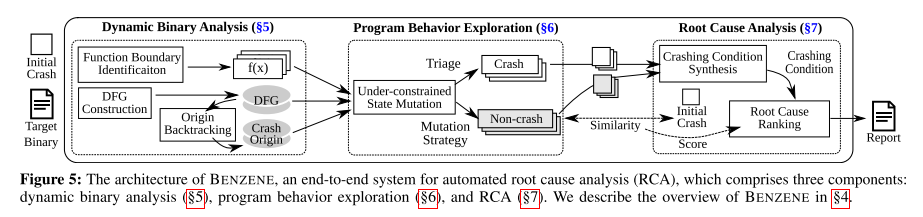

BENZENE 首先构建一个矩阵来描述每个收集到的行为的边缘覆盖范围,然后计算初始崩溃和非崩溃行为的覆盖范围之间的相似性得分。接下来,BENZENE 合成基于非崩溃行为描述崩溃条件的谓词。最后,BENZENE 使用崩溃条件的综合和每个非崩溃行为的相似性分数对导致给定崩溃的所有谓词进行排名。
欠约束状态变异可能会造成许多无意义的崩溃,所以归类有意义的崩溃至关重要。如果一个崩溃由状态突变触发的崩溃站点(即地址)与初始崩溃相同且执行与崩溃起源相关的指令。如果状态突变的崩溃满足上述条件,我们记录此行为;否则,我们将丢弃它。
- 边缘覆盖矩阵:与 AFL类似,我们利用广泛采用的边缘覆盖图来衡量模糊技术的性能。 BENZENE 在 64 KB 大小的地图上记录每个收集的行为的边缘覆盖信息(即基本块之间发生的转换)。地图随着迭代突变而不断更新。通过n种不同的行为,我们可以获得n(行)×64 KB(列)大小的边缘覆盖矩阵。一个值得注意的副作用是,具有非崩溃行为的执行的覆盖图将保持更新,直到程序终止,而具有崩溃行为的执行则不会。这不可避免地会导致用于比较的覆盖图之间存在显着差异,这阻碍了我们寻找与原始崩溃类似的非崩溃行为的主要目标。为了缓解这个问题,我们利用一个观察点来通知我们何时停止更新覆盖图。准确地说,观察点监视崩溃起源之一(第 6.3 节);一旦执行了崩溃触发的指令(来自给定的崩溃),覆盖图更新将被暂停以供后续执行。
- 基于 PCA 的相似度。为了减少边缘覆盖矩阵的维度,我们应用 PCA为每个收集的行为获得紧凑的覆盖图(图 8 中的 1)。然后,我们计算非崩溃行为的覆盖范围与初始崩溃之间的欧几里德距离(即 L2 范数)。 BENZENE 通过相似性分数(图 8 中的 2)确定具有某种非崩溃行为的执行与原始崩溃行为的执行有多接近:即距离越小,分数越接近。这种相似性评分允许对所有收集到的接近初始崩溃执行的非崩溃行为进行优先级排序。
本文作者:Du4t
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!