目录
🤣
SDFUZZ: Target States Driven Directed Fuzzing
作者
传统方案
之前的定向模糊法存在的一个主要问题是,它们通常会探索大量无法触发崩溃的程序代码和路径。在 DGF 的探索阶段,大多数现有方法都遵循 AFLGo 的解决方案,利用覆盖率反馈来扩大对不同代码区域的探索。许多代码区与目标站点无关,也不是到达目标站点所必需的。这些代码区仍在进行不必要的探索。在探索阶段,先前的定向模糊器利用基于控制流图(CFG)和调用图(CG)的距离度量。距离度量没有考虑路径条件,如控制流和数据流条件。因此,由于控制流或数据流条件不可满足而无法在目标站点触发漏洞的执行仍可能获得较短的距离,并被过分看好。这样就会浪费过多的测试工作。
缓解上述问题的解决方案是,首先确定引发崩溃所需的程序代码/路径,然后只对所需的代码/路径进行模糊测试。SieveFuzz 分析程序间控制流图(ICFG)以确定到达目标站点所需的函数,并在执行到非所需函数时终止执行[32]。Beacon 通过后向区间分析计算到达目标站点的先决条件,并提前终止不满足先决条件的执行[14]。SelectFuzz [20] 可静态识别目标站点的控制地数据依赖代码。但是,它们过度估计了允许的程序代码和路径集,大大限制了其性能。这是因为他们的分析是保守的。它们只考虑了控制流的可达性,却没有分析触发漏洞的其他条件,例如目标站点的预期到达顺序[16]。鹰眼[3]和 CAFL [16]在设计距离度量时包含了调用跟踪。但是,它们并没有利用这些代码/路径来排除不需要的代码/路径。
作者方案
通过对目标状态的新发现来缓解 DGF 中不必要的探索问题,目标状态包括触发漏洞的目标站点的预期调用轨迹和到达顺序。特别是,DGF 的主要任务,如崩溃再现和漏洞验证,都提供了对漏洞的详细描述,如目标站点位置和相关漏洞信息,如崩溃转储、回溯[10]和源-汇流[35]。目标站点位置描述了漏洞发生的位置;漏洞信息还解释了如何触发漏洞的有趣程序状态(即目标状态)。定向模糊的目标不仅是到达目标站点位置,还包括动态暴露漏洞。受此启发,我们不仅要将模糊测试推向目标站点,还要推向有趣的目标状态。因此,除了排除无法到达目标站点的探索之外,我们还进一步避免了无法到达目标状态的不必要执行。
在运行时,SDFUZZ 会维护运行时程序状态,定期将其与目标状态进行比较,并探测是否存在偏差。在随后执行测试用例时,如果出现无法挽回的偏差,就会立即终止。如果 ICFG 上有程序路径,偏差函数调用有可能更新为目标状态中指定的预期函数调用,则偏差可以恢复。
更新的反馈机制
- SDFUZZ 通过计算模糊试验的最佳运行时程序状态与目标状态的相似度得分,计算新的目标状态反馈。
- SDFUZZ 改进了 DGF 中广泛采用的距离度量。在 CG 中,SDFUZZ 没有使用根据经验配置的常量系数(如 AFLGo 中的 10)作为函数间的程序间距,而是使用了一种新的加权程序间距,它近似于调用方函数调用被调用方函数的几率。
Q1: 作者是如何定义状态的
在这项工作中,我们将目标站点的预期调用轨迹和到达顺序定义为目标状态。我们将程序状态(PS)形式化为函数调用的堆栈(调用位置)。程序状态中的每个项目都是函数名和调用位置((Func, Loc))的元组。漏洞或错误的目标状态(TS)就是它被触发时的程序状态。要达到目标状态,其中的函数必须以正确的顺序达到或调用。


针对上述样例可以描述为

整体架构
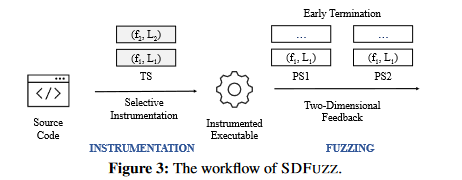
- SDFUZZ 首先自动提取目标状态,并将其解析为指定格式。
- SDFUZZ 确定达到目标状态所需的代码,并从模糊测试中删除其他不需要的代码。
- SDFUZZ 采用两维反馈机制,主动引导测试达到目标状态
Q2: “一旦 SDFUZZ 发现测试用例的剩余执行无法达到目标状态,它就会提前终止执行,从而提高模糊吞吐量(即单位时间内的执行次数)” 怎么确定?
其实就是对比程序状态列表,如果程序步入了不在列表中的函数,就检查ICFG查看该函数是否在可能到达目标函数的路径上,如果不在就终止执行。
提取目标状态
Vulnerability reports
崩溃转储由漏洞触发时的活动函数调用记录组成,如图 2 所示。每条记录包含函数名称(如 option1)和调用位置(如 file.c:15)。因此,我们首先使用正则表达式搜索漏洞报告中包含此类信息的描述。提取后,我们进一步解析,以确定它们是否符合公式 1 中定义的格式。我们还会根据漏洞类型和描述自动对目标状态进行排序。例如,一个UAF漏洞通常包含多个目标状态。我们将按照free和use地点对目标状态进行排序。
Static Analysis Result
SDFUZZ 还能从静态分析结果中自动提取目标状态。由于不同的静态分析工具采用不同的方式来表示其结果,因此自动提取自然必须针对每种静态分析工具进行专门设计。我们目前开发的 SDFUZZ 与一种流行的静态分析工具 SVF [34, 35]相协调。据我们所知,目标状态也可以从其他静态分析工具(如 CodeQL [9] 和 Joern [39])中提取,只需对结果进行额外的解析即可。运行此类静态分析工具通常需要程序的源代码。
Selective Instrumentation
我们的解决方案是有选择性地为代码覆盖率反馈检测所需的代码,而不是直接将其从源代码或可执行文件中删除。我们提出了一种函数级算法(如算法 1 所示)来识别所需的代码。该算法将一组目标状态(TS)和目标程序的 ICFG(ICFG)作为输入。目标状态中出现的函数(即目标状态函数)与漏洞相关,并直接作为所需函数(第 5 行)。此外,这些目标状态函数还可能依赖于其他函数。我们的算法首先会进行程序内反向分析,以确定目标状态函数所依赖的函数(第 6 行)。如果在具有函数调用位置的基本程序块和目标状态函数的基本程序块之间存在程序内路径,则该函数将被包括在内。

Early Termination
为了提前终止执行,我们必须预测执行最终能否到达目标状态。这很困难,因为程序状态会在程序执行过程中动态更新,例如通过函数调用和返回。鉴于现代程序的高复杂性,它们所能展现的程序状态空间可能是巨大的。
Runtime Program State Monitoring. SDFUZZ 监控运行时的函数调用,并记录函数调用的堆栈。这些函数通过函数调用或返回从堆栈中push或pop。通过函数调用位置,SDFUZZ 可以区分在不同位置调用的相同函数。程序状态跟踪可能会导致状态爆炸[38],并造成很大的开销。我们只跟踪与目标状态相关的函数的状态,从而缓解了这一问题。特别是,SDFUZZ 只在程序调用或返回目标状态下的函数时更新和检查程序状态,以防提前终止。
An unrecoverable deviation based solution. 多目标漏洞的目标状态是函数调用的有序列表数组,每个列表针对一个目标点。因此,我们的算法(如算法 2 所示)将某个时间点的当前程序状态 (PS)、先前达到的目标状态 (reachedTSs)、有序目标状态 (TSs) 和 ICFG 作为输入。它对目标状态进行迭代,以找到在测试用例的模糊测试过程中未达到的第一个目标状态(第 3-6 行)。如果所有目标状态都已达到,算法将直接返回(第 7-8 行)。否则,算法将检查偏差函数调用,尤其是通过根偏差函数检查第一个偏差-根偏差(第 10 行)。根偏差表示程序状态开始偏离未达到的目标状态的位置。这是通过反复比较调用点(第 20-26 行)来找到第一个偏差。

如果出现任何偏差(第 11 行),我们的算法会根据 ICFG 进一步衡量剩余的执行是否能恢复偏差以达到目标状态(第 12 行)。如果一个执行程序的程序状态出现无法恢复的偏差,就会被立即终止。我们的算法会检查程序的 ICFG,并探测是否存在从根偏差代码位置到目标状态中预期函数调用的程序路径。这样的路径意味着偏差可能会在未来的执行中恢复,因为执行可以从根偏差函数调用返回并运行到预期函数调用。因此,可能恢复偏差的执行不会终止。
Two-Dimensional Feedback
为了快速将模糊推向目标状态,SDFUZZ 按照目标状态反馈和种子距离这两个属性对语料库中的种子进行排序。一般来说,SDFUZZ 会优先选择目标状态反馈较好、距离较短的种子。它将目标状态反馈作为主要排序属性,将距离作为次要排序属性。原因是目标状态反馈捕捉到的运行时上下文更精确,能更好地帮助接近目标状态。SDFUZZ 还改进了 AFLGo 的能量调度算法,根据二维反馈为种子分配能量。
Target State Feedback
找到第一个未达到的目标状态(nextTS)后,SDFUZZ 使用根偏差指数计算相似度得分。如果当前程序状态与第一个未达到的目标状态(nextTS)不完全匹配,SDFUZZ 会首先通过计算匹配偏差 Idx 与其大小之比来衡量当前程序状态与目标状态的匹配程度(第 13 行)。我们的算法还考虑了之前达到的目标状态,并将达到的目标状态的比率和大小相加得出分数。分数会根据目标状态的数量进一步归一化,然后返回。如果当前程序状态与 nextTS 匹配,我们的算法会直接返回已达到目标状态的比例(第 16 行)。由于执行一个测试用例时可能会多次调用该算法,因此我们将最佳得分作为测试用例的结果。
Distance Feedback
先前的距离度量并不精确,因为它们对 CG 中的每条边都一视同仁。SDFUZZ 通过精确的边缘权重来减轻不精确性。边缘权重有望反映调用方函数调用被调用方函数的机会。SDFUZZ 根据调用点权重计算边缘权重。
我们将调用方函数调用被调用方函数的调用点权重定义为 从调用方函数的起点到被调用方函数的调用点的过程内距离(即 AFLGo中最短路径上的基本块距离)。
由于同一个被调用函数可能有多个调用点,因此程序间边权重是调用方函数和被调用方函数 之间的最短调用点权重。
其中是函数的程序内距离
本文作者:Du4t
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!