目录
🤔
Critical Code Guided Directed Greybox Fuzzing for Commits
作者
-
Yi Xiang - 浙江大学、浙江大学 NGICS 平台
-
Xuhong Zhang - 浙江大学博导、江淮前沿技术协同创新中心 - 可信计算、
-
Peiyu Liu - 浙江大学、浙江大学 NGICS 平台 -
-
Shouling Ji - 浙江大学博导 - 机器学习、模糊测试
-
…
-
Wenhai Wang - 浙江大学博导、浙江大学 NGICS 平台 - 控制系统安全
传统做法
针对与新提交内容的Fuzz
- 现有的定向模糊器主要集中于达到单一目标,而忽视了对其他受影响代码的多样化探索。因此,它们可能会忽略在远离变更站点的地方崩溃的错误
- 在多目标场景中缺乏直接性
现有方法无法解决的问题
- 如何快速、彻底地测试受影响的代码?到达目标后,如何探索受影响代码的不同程序状态?
- 如何以智能和轻量级的方式处理多个目标的定向模糊测试?
作者的方案
Key insight: 在生成可探索不同程序状态的输入的同时,保留关键代码的执行
作者细分出来两种代码
-
路径前缀代码(path-prefix Code): 能影响变化点的控制流的代码
- 罕见的路径前缀代码: 表示通向目标的新路径
-
数据后缀代码(data-suffix Code): 与变化点中使用的关键变量有数据依赖关系的代码
- 罕见的数据后缀代码: 表示可能影响受影响代码的新数据值
在变异种子时,会检查它是否执行了任何关键代码。如果发现了关键代码,我们就会为种子生成一个突变掩码,并应用细粒度突变来维持其在生成输入中的执行。否则,我们会采用粗粒度变异来增强种子的多样性。
在模糊处理过程中,我们会根据种子是否到达目标来选择目标边缘。如果种子没有到达目标,我们就从种子执行的路径前缀代码中选择离目标 "最近 "的边作为目标边。通过只改变不偏离目标边的输入字节,我们会逐渐生成更接近目标的输入。如果种子已经达到目标,我们会从路径前缀和数据后缀中选择最罕见的执行边作为目标边,对受影响的代码进行全面测试。
Q1: 如何自动化定义关键代码,如何轻量级观察是否执行了关键代码?
通过ICFG反向查找所有从起始到达目标点的路径将其作为路径前缀代码
通过SVFG也就是前向数据流分析来定位相关数据流依赖的代码作为数据后缀代码
Q5: ICFG识别完整性问题?开销问题?
整体架构
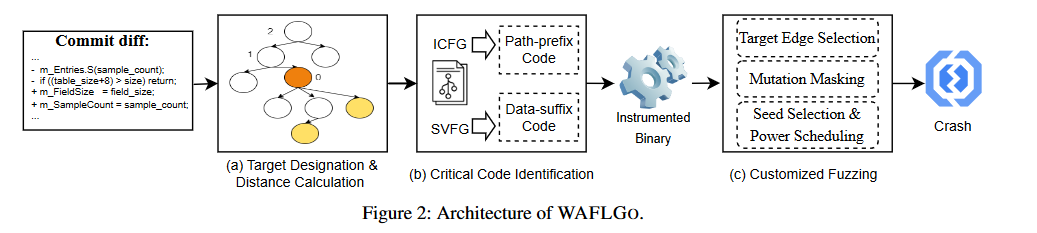
目标合并
作者的目标主要是新commit上去的代码,一般来说一个commit包含的功能的patch是相似的。
说人话就是多个commit可能是与同一个功能相关的patch,作者提出了一种算法以功能点作为聚类将多个patch点合并
由于一个函数中的变化有很多相似的前提条件,因此我们将同一个函数中的所有变化位点合并为一个。首先构造目标函数的支配树,然后将目标函数中每个初始目标的直接支配树作为该函数的合并目标。
Q2: 没明白怎么合并目标
简单来说就是将所有存在更改的站点打上污染tag,然后生成支配树如果这些tag在一颗支配树中就认为是同一个目标,对其进行合并
距离算法
: 包含合并目标的基本块称为目标基本块
: 一个基本块m到每个目标块的距离为
: 两个基本块和之间的距离为两个基本块之间的最短路径所包含的基本块数量
: 对于一个边来说,其中分别表示边的起点和终点。将边到基本块的距离定义为
: 令为种子的执行路径,对于每个目标我们定义种子的输入距离为 其中
Q3: 这个距离定义和AFLGO有什么区别?
没有区别
关键代码识别
-
路径前缀代码: 指所有能够导致目标代码执行的代码。它包括ICFG中与目标代码直接或间接相连的代码块。
-
数据后缀代码: 包括依赖于初始目标中使用关键变量的代码
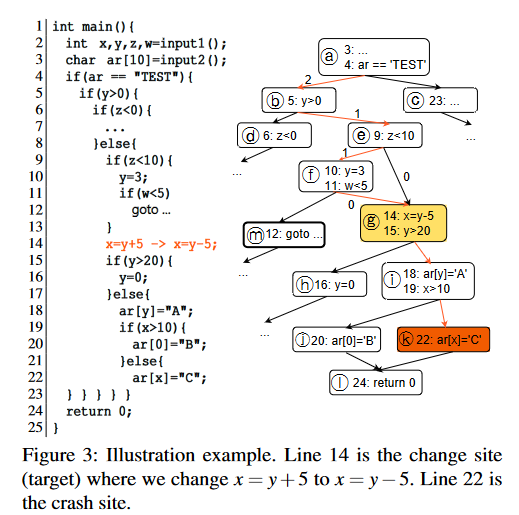
在此例子中,开发者对第14行也就是基本块g进行了修补将x=y+5修补为x=y-5,将Patch基本块中被写入的变量作为污染变量,向后传递污染使用被污染变量的基本块并将其作为数据后缀代码。在这个例子中数据后缀代码为:i、k 而路径前缀代码比较直接,就是从起点导向目标块的路径,在这个例子中路径前缀代码为:a、b、e、f
关键代码导向的模糊测试
针对于定向模糊测试有两个重要的种子生成指标
- 是否能够到达目标位置
- 在到达目标位置之后能否保持目标位置的可达性而后继续生成不同的输入
整体WAFLGO的算法大致如下

目标达到阶段

简单来说,就是挑选覆盖到离目标最近的边的种子进行变异,同时在执行过程中记录覆盖次数,当覆盖次数大于阈值时进行回退,继续变异覆盖到除了该边外离目标站点最近的边
Q4: 这样做的合理性在哪里,和传统的AFLGO基于距离的定向模糊测试有什么区别?
没有区别,后文作者提到了这种做法跟AFLGO传统的模拟退火算法没啥区别,但是反馈粒度更细。
综合测试阶段
在此阶段中主要利用路径前缀代码和数据后缀代码进行多样化变异。
当有测试样例到达目标位置之后仍然会继续根据最近的边进行变异,只有当所有的边覆盖次数都超过阈值时测试会转向数据后缀代码。在此基础上会选定覆盖次数最少得数据后缀代码的边作为目标继续测试。
在此例中,如果给出一个种子其能够覆盖到,最开始选定的测试边为而后是、,当所有的边都到达指定的阈值之后就将作为目标边进行Fuzz。
变异掩码生成
使用的方法非常简单,就是使用一组预定义好的突变算子逐字节的对种子进行变异,如果变异某字节之后仍然能够到达目标边就将对应字节标记为可变异字节,并且更新掩码。在随后的变异中可变异字节将会以更高的概率被选中进行变异。
Q5: 这样做如果某个边是依赖于多个字节同时进行变异呢?
没有影响
种子选择和能量调度
作者首先维护了一个高优先级队列,其内部主要保存新触发关键代码的种子,在变异过程中有更高的概率选中高优先级队列中的种子进行变异。
在能量调度方面,在未覆盖目标之前采用的是跟AFLGO一样的模拟退火算法,并且会将更多能量分配给更接近最稀有执行目标的种子。在覆盖目标之后将忽略模拟退火算法而关注数据后缀代码的代码覆盖度,从而会将更多能量分配给覆盖更多数据后缀代码的输入。
Question
仍然存在调用图识别不全等问题,而且对于如此细粒度的跟踪开销仍然是个巨大的问题。
同时在目标到达阶段其实仍然是AFLGO那套东西,模拟退火算法只是粒度更细,真实效果存在疑问。
本文作者:Du4t
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!